













統合コンパクション戦略 (UCS)
統合コンパクション戦略 (UCS) は、読み取り負荷の高い、書き込み負荷の高い、読み書きが混在する、時系列など、ほとんどのワークロードに推奨されます。UCS は既存のコンパクション戦略のように動作するように設定できるため、既存のコンパクション戦略を使用する必要はありません。
UCS は、他の戦略の利点と新機能を組み合わせたコンパクション戦略です。 UCS は、高密度ノードにとって重要なコンパクションの速度を最大化するために設計されており、パーティション化されたデータを並列にコンパクションする独自のシャーディングメカニズムを使用します。 また、STCS、LCS、または TWCS は、コンパクション戦略が変更された場合にデータの完全なコンパクションが必要になりますが、UCS は実行中にパラメータを変更して、ある戦略から別の戦略に切り替えることができます。 実際、階層の各レベルに異なるパラメータを設定することで、異なるコンパクション戦略の組み合わせを同時に使用できます。 最後に、UCS はステートレスであるため、コンパクションの決定を行うためにメタデータに依存しません。
2 つの重要な概念により、グループ化の定義が洗練されます
-
階層型コンパクションとレベル型コンパクションは、どちらも SSTable(または重複しない SSTable ラン)の**サイズ**に基づいて指数関数的に増加するレベルを作成するため、同等とみなすことができます。 したがって、1 つのレベルに指定された数を超える SSTable が存在する場合にコンパクションがトリガーされます。
-
**サイズ**を**密度**に置き換えることで、コンパクションの出力が書き込まれるときに SSTable を任意のポイントで分割できるようになり、レベル化された階層が生成されます。 密度とは、SSTable のサイズを、SSTable がカバーするトークン範囲の幅で割った値として定義されます。
最初の概念を詳しく見てみましょう。
読み取りと書き込みの増幅
UCS は、読み取りに対応するために参照される SSTable の数(読み取り増幅、または RA)と、データが有効期間中に書き換えられる必要がある回数(書き込み増幅、または WA)のバランスを調整できます。 単一の構成可能なスケーリングパラメータにより、読み取り負荷の高いモードから書き込み負荷の高いモードまで、コンパクションの動作が決まります。 スケーリングパラメータはいつでも変更でき、コンパクション戦略はそれに応じて調整されます。 たとえば、オペレーターは次のことを決定できます。
-
特定のテーブルの読み取り負荷が高く、レイテンシの削減によるメリットが得られる場合、スケーリングパラメータを小さくして読み取り増幅を下げ、書き込みの複雑さを増す
-
テーブルへの書き込み数にコンパクションが追いつかないことが判明した場合、スケーリングパラメータを大きくして書き込み増幅を削減する
このような変更は、階層を新しい構成と互換性のある状態にするために必要なコンパクションのみを開始します. すでに実行された追加の作業 (たとえば、負のパラメータから正のパラメータに切り替える場合) は有利であり、組み込まれます。
さらに、スケーリングパラメータを高い階層型ファンアウトファクタをシミュレートするように設定することにより、UCS は TWCS と同じコンパクションを実行できます。
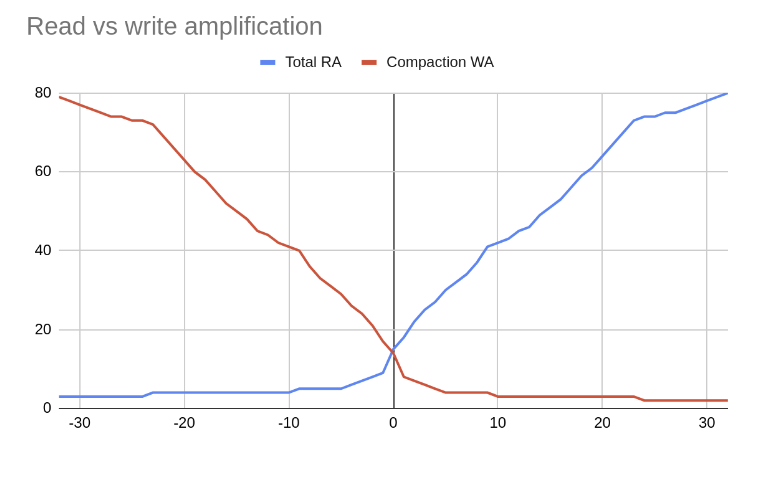
UCS は、階層型コンパクションとレベル型コンパクション、およびシャーディングを組み合わせて、目的の読み取りと書き込みの増幅を実現します。 SSTable はトークン範囲でソートされ、レベルにグループ化されます
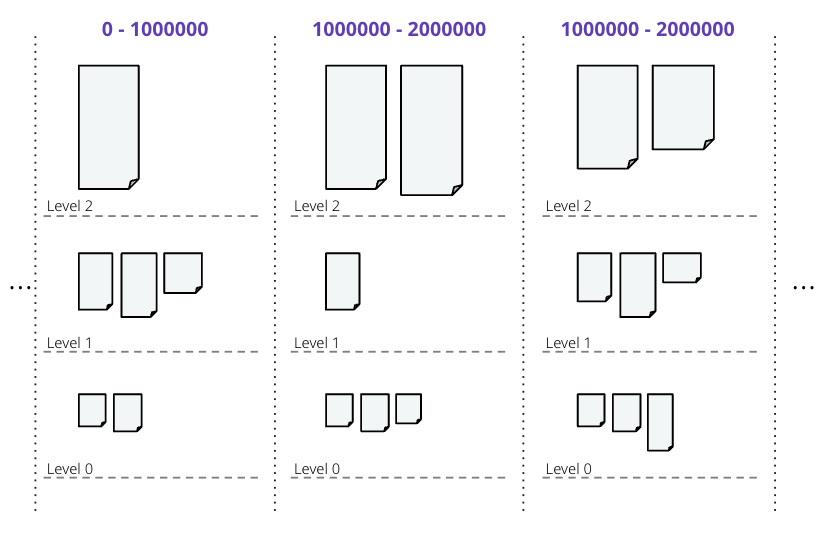
UCS は、SSTable の密度の対数を基準にして SSTable をレベルにグループ化します。ファンアウトファクタ \(f\) を対数の底とし、各レベルは \(t\) 個の重複する SSTable が存在するとすぐにコンパクションをトリガーします。
スケーリングパラメータ \(w\) の選択により、ファンアウトファクタ \(f\) の値が決まります。 次に、\(w\) はモードをレベル型または階層型のいずれかとして定義し、\(t\) はレベル型コンパクションの場合は \(t=2\)、階層型コンパクションの場合は \(t=f\) として設定されます。 UCS の完全な動作を決定するには、最後のパラメータである最小 SSTable サイズが必要です。
上記の RA と WA の図に示すように、\(w\) の値に基づいて、3 種類のコンパクションが可能です。
-
WA が高く、RA が低いレベル型コンパクション: \(w < 0\)、\(f = 2 - w\) および \(t=2\)。 \(L_{f}\) は、この範囲の \(w\) 値を指定するための略記です (たとえば、\(w=-8\) の場合は L10)。
-
WA が低く、RA が高い階層型コンパクション: \(w > 0\)、\(f = 2 + w\) および \(t=f\)。 \(T_{f}\) は略記です (たとえば、\(w = 2\) の場合は T4)。
-
レベル型コンパクションと階層型コンパクションは、中央で同じように動作します: \(w = 0\) および \(f = t = 2\)。 略記では、\(w = 0\) の場合は N です。
|
レベル型コンパクションは書き込みを犠牲にして読み取りを改善し、\(f\) が増加するにつれてソートされた配列に近づきます。一方、階層型コンパクションは読み取りを犠牲にして書き込みを優先し、\(f\) が増加するにつれてソートされていないログに近づきます。 |
UCS では、\(w\) の値をレベルごとに個別に定義できます。したがって、レベルは異なる動作を持つことができます。 たとえば、レベルゼロは階層型コンパクション (STCS 的) を使用でき、上位レベルは読み取り最適化のレベルが上がるレベル型 (LCS 的) にすることができます。
サイズに基づくレベル化
この戦略では、SSTable の密度とともに数が増加する特定のシャード境界で SSTable を分割します。 分割によって作成された SSTable 間の重複がないため、同時コンパクションが可能になります。 ただし、ここでは密度と分割は無視して、SSTable が分割されない場合に SSTable がどのようにレベルにグループ化されるかを見てみましょう。
Memtable はレベルゼロ (L0) にフラッシュされ、memtable フラッシュサイズ \(s_{f}\) は、memtable がフラッシュされたときに書き込まれたすべての SSTable の平均サイズとして計算されます。 このパラメータ \(s_{f}\) は、新しくフラッシュされたすべての SSTable が配置される階層の基礎を形成することを目的としています。 固定ファンアウトファクタ \(f\) と \(s_{f}\) を使用すると、サイズ \(s\) の SSTable のレベル \(L\) は次のように計算されます。
SSTable はサイズに基づいてレベルに割り当てられます
| レベル | 最小 SSTable サイズ | 最大 SSTable サイズ |
|---|---|---|
0 |
0 |
0 |
1 |
0 |
\(s_{f}\) |
2 |
\(s_{f}\) |
\(s_{f} \cdot f\) |
3 |
\(s_{f} \cdot f\) |
1 |
\(s_{f} \cdot f\) |
\(s_{f} \cdot f\) |
\(s_{f} \cdot f\) |
\(s_{f} \cdot f^2\) |
2 |
\(s_{f} \cdot f^2\) |
\(s_{f} \cdot f^3\)
-
3
-
\(s_{f} \cdot f^3\)
-
\(s_{f} \cdot f^4\)
-
…
-
-
n
-
\(s_{f} \cdot f^n\)
-
\(s_{f} \cdot f^{n+1}\)
各コンパクション戦略の読み取りと書き込みの増幅は、階層内のレベルの数に比例します
戦略
読み取り増幅
レベル型
-
\(\varpropto\) レベルの数の \(f-1\) 倍
-
\(\varpropto\) レベルの数
-
階層型
-
\(\varpropto\) \(\frac{f}{2}\)
-
f の値が大きくなるにつれて、ソート済み配列の動作に近づきます。
-
-
t = f = 2 の場合のコンパクション。レベリングは階層化と同じで、読み取りと書き込みのコストが対数的に増加する中間的な状態になります。
-
f の値が大きい階層型コンパクション (t=f)
-
非常に多くの SSTable
-
低い読み取り効率
-
低い書き込みコスト
-
f の値が大きくなるにつれて、ソートされていないログに近づきます。
-
これは、べき乗をすべての下位レベルのファンファクターの積に置き換えることで、さまざまなファンファクターに簡単に一般化できます。
| レベル | 最小 SSTable サイズ | 最大 SSTable サイズ |
|---|---|---|
0 |
0 |
\(s_{f} \cdot f_0\) |
1 |
\(s_{f} \cdot f_0\) |
\(s_{f} \cdot f_0 \cdot f_1\) |
2 |
\(s_{f} \cdot f_0 \cdot f_1\) |
\(s_{f} \cdot f_0 \cdot f_1 \cdot f_2\) |
\(s_{f} \cdot f\) |
\(s_{f} \cdot f\) |
\(s_{f} \cdot f\) |
\(s_{f} \cdot f^2\) |
\(s_{f} \cdot \prod_{i < n} f_i\) |
\(s_{f} \cdot \prod_{i\le n} f_i\) |
密度ベースのレベリング
上記の議論におけるサイズ s を密度指標に置き換えると、
ここで、v は SSTable がカバーするトークンスペースの割合です。すべての式と結論は有効です。ただし、密度を使用することで、出力は任意のポイントで分割できるようになります。複数の SSTable を圧縮して分割すると、新しく生成される SSTable は元の SSTable よりも密度が高くなります。たとえば、スケーリングパラメータ T4 を使用して、トークンスペースの 1/10 をそれぞれカバーする 4 つの入力 SSTable を圧縮して分割すると、トークンスペースの 1/40 をそれぞれカバーする 4 つの新しい SSTable が形成されます。
これらの新しい SSTable はサイズは同じですが密度が高いため、元の圧縮レベルの最大密度を超える高い密度値により、次の上位レベルに移動されます。分割点が固定されていることを保証できれば(下記参照)、このプロセスは各シャード(トークン範囲)に対して繰り返され、独立した圧縮が並行して実行されます。
|
v を計算する際には、ローカルで所有するトークンシェアを考慮することが重要です。仮想ノードは、ノードのローカルトークン所有権が連続していないことを意味するため、最初と最後のトークンの差はトークンシェアを計算するには不十分です。したがって、ローカルで所有されていない範囲はすべて除外する必要があります。 |
密度指標を使用すると、シャーディングによって SSTable のサイズを制御し、圧縮を並行して実行できます。サイズレベリングコンパクションでは、データディレクトリに基づいて、固定数のコンパクションシャードにデータを事前に分割することで並列化を実現できました。ただし、この方法では、シャードの数を事前に決定し、階層のすべてのレベルで同じにする必要があります。また、SSTable が小さすぎる、または大きすぎる可能性があります。大きな SSTable は、ストリーミングと修復を複雑にし、コンパクション操作の期間を延長し、リソースを長時間実行される操作に固定し、階層の下位レベルに過剰な SSTable が蓄積される可能性を高めます。
密度レベリングコンパクションでは、はるかに幅広い分割オプションが可能です。たとえば、SSTable のサイズを選択したターゲットの近くに維持できるため、UCS は STCS(SSTable のサイズはレベルごとに増加する)と LCS(トークンシェアはレベルごとに縮小する)の両方のレベリングに対処できます。
シャーディング
基本的なシャーディングスキーム
このシャーディングメカニズムは、コンパクション仕様とは無関係です。SSTable を分割するための選択肢はいくつかあります。
-
特定の出力サイズに達したときに分割する(LCS など)。個々の SSTable ではなく、重複しない SSTable ランを形成します。
-
トークンスペースを事前に定義された境界点でシャードに分割する
-
事前に定義された境界で分割するが、特定の最小サイズに達した場合のみ
サイズのみで分割すると、開始位置が異なる個々の SSTable が生成されます。このように分割された SSTable を圧縮するには、レベル全体のトークン範囲を順番に圧縮するか、重複する SSTable により、必要以上に何度もデータを圧縮してコピーする必要があります。事前に定義された境界点を使用すると、トークン範囲の一部が入力が少なくなり、結果の SSTable の密度が歪む可能性があります。その場合、さらに分割が必要になる場合があります。ハイブリッドオプションでは、密度の歪みが発生する頻度は少なくなりますが、それでも発生する可能性があります。
これらの問題を回避し、コンパクション階層のすべてのレベルの同時コンパクションを可能にするために、UCS はすべてのコンパクションの境界点を事前に定義し、常にこれらのポイントで SSTable を分割します。境界の数は、入力 SSTable の密度と結果の SSTable の推定密度から決定されます。密度が大きくなるにつれて、境界の数は増加し、個々の SSTable のサイズを事前に定義されたターゲットの近くに維持します。指定されたベースカウントの 2 のべき乗の倍数を使用する、つまりシャードを中央で分割することで、特定の出力密度に適用される境界がすべての上位密度にも適用されるようになります。
2 つのシャーディングパラメータを設定できます。
-
ベースシャードカウント b
-
ターゲット SSTable サイズ st
すべてのコンパクションの開始時に、出力の密度 d は、SSTable の入力サイズ s とトークン範囲 v に基づいて推定されることを思い出してください。
ここで、v は入力 SSTable によってカバーされるトークン範囲の割合であり、0 から 1 の値です。v = 1 は、トークン範囲全体が入力 SSTable によってカバーされていることを意味し、v = 0 は、入力 SSTable がトークン範囲をカバーしていないことを意味します。
memtable から L0 への最初のフラッシュが発生すると、トークン範囲全体が memtable に含まれるため、v = 1 になります。後続のコンパクションでは、トークン範囲 v は、圧縮される SSTable によってカバーされるトークン範囲の割合です。
計算された出力の密度と、b と st の値を使用して、トークンスペースを分割するシャードの数 S を計算できます。
ここで、\(\lfloor x \rceil\) は、x を最も近い整数に丸めた値、つまり \(\lfloor x + 0.5 \rfloor\) を表します。したがって、2 番目のケースでは、密度はターゲットサイズで除算され、b の 2 のべき乗の倍数に丸められます。結果が 1 未満の場合、memtable は {2 \cdot b}、つまり b 個の L0 シャードに分割されるため、シャードの数はベースシャードカウントになります。
ただし、b シャードとそれ以上のシャードを切り替えるかどうかに影響を与える要因は、トークン範囲だけではありません(条件が 1 以上の場合)。memtable が非常に大きく、一度に数ギガバイトをフラッシュできる場合、d は st よりも桁違いに大きくなる可能性があり、L0 でも SSTable が複数のシャードに分割される可能性があります。逆に、memtable が小さい場合、条件が 1 未満の上位レベルの L0 では、d は st よりも小さいままである可能性があり、したがって、stem[b] シャードが存在します。
S - 1 個の境界が生成され、ローカルトークンスペースが S 個のシャードに均等に分割されます。ローカルトークンスペースを分割すると、これらの境界でコンパクションの結果が分割され、各シャードに個別の SSTable が形成されます。生成される SSTable のサイズは、\(s_{t}/\sqrt 2\) から \(s_{t} \cdot \sqrt 2\) の間になります。
たとえば、ターゲット SSTable サイズ st = 100MiB と b = 4 ベースシャードを使用してみましょう。sf = 200 MiB の入力 memtable がフラッシュされる場合、シャードの数を計算するための条件は次のとおりです。
最初のフラッシュでは v = 1 の値になるため、この計算の結果は 0.5 < 1 になります。結果が 1 未満であるため、ベースシャードカウントが使用され、memtable は約 50MiB ずつの 4 つの L0 シャードに分割されます。各シャードはトークンスペースの 1/4 に及びます。
例を続けると、次のレベルのコンパクションでは、4 つのシャードのうちの 1 つだけについて、これらの 50 MiB SSTable のうち 6 つを圧縮してみましょう。出力の推定密度は次のようになります。
入力 SSTable によってカバーされるトークン範囲の v 値として 1/4 を使用します。
分割の条件は次のとおりです。
したがって、シャードの数は次のように計算されます。
または、\(2^{\log_2 3}\) を、ローカルトークンスペース全体で \(2^2 \cdot 4\) シャードに丸め、トークンスペースの 1/4 をカバーするコンパクションを行います。上書きまたは削除がないと仮定すると、結果の SSTable のサイズは 75 MiB、トークンシェアは 1/16、密度は 1200 MiB になります。
完全なシャーディングスキーム
このシャーディングスキームは簡単に拡張できます。現在実装されている拡張機能は 2 つあります。SSTable の増加と SSTable の最小サイズです。
まず、データセットのサイズが非常に大きくなると予想される場合について調べてみましょう。SSTable あたりのオーバーヘッドの問題を回避するために十分な大きさのターゲットサイズを事前に指定することを避けるために、`SSTtable growth` パラメータが実装されました。このパラメータは、密度増加のどの部分を SSTable サイズの増加に割り当てるかを決定し、シャード数の増加、つまり重複しない SSTable の増加を削減します。
2 番目の拡張機能は、最小サイズに達した場合に条件付きで分割する、固定数のシャードを使用した動作モードです。`minimum SSTable size` を定義することで、分割によって提供された最小値よりも小さい SSTable が生成される場合は常に、ベースシャードカウントを削減できます。
ユーザー定義のシャーディングパラメータは 4 つあります。
-
ベースシャードカウント b
-
ターゲット SSTable サイズ st
-
最小 SSTable サイズ sm
-
SSTable 成長コンポーネント λ
特定の密度 d に対するシャードの数 S は、次のように計算されます。
これらのパラメータの便利な組み合わせをいくつか示します。
-
上記の 基本スキームでは、SSTable の増加 λ=0 と最小 SSTable サイズ sm=0 を使用します。以下のグラフは、ベースシャードカウント b=4 とターゲット SSTable サイズ st = 1 GB の場合の動作を示しています。

-
λ = 0.5 を使用すると、シャードカウントと SSTable サイズが均等に増加します。密度が 4 倍になると、シャードカウントと、その密度帯域の予想 SSTable サイズの両方が 2 倍になります。以下の例では、b=8、st = 1 GB を使用し、最小サイズ m = 100 MB も適用しています。

-
同様に、\(\lambda = 1/3\) とすると、SSTable の増加は密度増加の立方根となり、つまり、SSTable のサイズはシャード数の増加の平方根に比例して増加します。以下のグラフは、\(b=1\) および \(s_{t} = 1\, \mathrm{GB}\) を使用しています(注:\(b=1\) の場合、最小サイズは効果がありません)。

-
増加成分が 1 の場合、すべてのレベルで正確に \(b\) 個のシャードを持つ階層が構築されます。最小 SSTable サイズと組み合わせることで、この動作モードでは事前に指定された数のシャードを使用しますが、最小サイズに達した後にのみ分割が行われます。以下は、\(b=10\) および \(s_{m} = 100\, \mathrm{MB}\) の場合の例です(注:\(\lambda=1\) の場合、ターゲット SSTable サイズは無関係です)。

コンパクション対象の SSTable の選択
密度レベリングは、コンパクション設定のファンファクターによって定義されたレベルで SSTable を分離します。ただし、SSTable がトークンスペース全体をカバーすることが想定されているサイズレベリングとは異なり、重複しない SSTable が存在する可能性があるため、レベルの SSTable の数をトリガーとして使用することはできません。この状況では、読み取りクエリの効率が低下します。これに対処するために、レベルで同時に複数のコンパクションを実行し、個々のコンパクション操作のサイズを削減するシャーディングを実行します。重複しないセクションは異なるバケットに分離する必要があり、バケット内の重複する SSTable の数によって、何を行うかが決定されます。バケットとは、一緒にコンパクションされる SSTable の選択されたセットです。
最初に、以下の要件を満たす重複セットの最小リストを作成します。
-
重複しない 2 つの SSTable は、同じセットに配置されません。
-
2 つの SSTable が重複する場合、リストには両方の SSTable を含むセットが存在します。
-
SSTable はリスト内で連続した位置に配置されます。
2 番目の条件は、トークン範囲内の任意のポイントについて、そのポイントをカバーする範囲を持つすべての SSTable を含むセットがリストに存在する、と言い換えることもできます。言い換えれば、重複セットは、任意のキーを読み取るために参照する必要がある SSTable の最大数、つまり、トリガー \(t\) が制御しようとする読み取り増幅を提供します。重複するセットがカバーする正確な範囲は計算または保存せず、参加している SSTable のみを保存します。セットは \(O(n\log n)\) 時間で取得できます。
たとえば、SSTable A、B、C、D がそれぞれトークン 0-3、2-7、6-9、1-8 をカバーする場合、重複セット ABD と BCD のリストを計算します。A と C は重複しないため、別々のセットに配置する必要があります。A、B、D はトークン 2 で重複するため、少なくとも 1 つのセットに存在する必要があります。B、C、D についてもトークン 7 で同様です。A と D のみがトークン 1 で重複しますが、セット ABD にはこの組み合わせが既に含まれています。
これらの重複セットは、セット内の要素の数が \(s_{t}\) 以上である場合にのみ、コンパクションを実行する必要があるかどうかを決定するのに十分です。ただし、このセット単体よりも多くの SSTable をコンパクションに含める必要がある場合があります。
シャーディングスキームでは、同じレベルで異なるサイズのシャードにまたがる SSTable が構築される可能性があります。明確な例としては、レベリングコンパクションの場合が挙げられます。この場合、SSTable はある密度で入り、最初のコンパクション後、結果の SSTable は初期密度の 2 倍の大きさになり、SSTable はトークン範囲の中央で半分に分割されます。別の SSTable が同じレベルに入ると、2 つの古い SSTable と新しい SSTable の間に別々の重複セットが作成されます。効率を高めるために、次にトリガーされるコンパクションでは、両方の重複セットを選択する必要があります。
部分的な重複の場合に対処するために、重複セットは、一部の SSTable を共有するすべての隣接するセットに推移的に拡張されます。したがって、構築されたすべての SSTable のセットには、初期セットに接続する重複する SSTable のチェーンがあります。この拡張セットは、コンパクションバケットを形成します。
|
|
通常の操作では、コンパクションバケット内のすべての SSTable をコンパクションします。コンパクションが非常に遅い場合は、コンパクションする重複ソースの数に制限を適用する場合があります。その場合、含まれる重複セットで最大 limit 個を選択する最も古い SSTable のコレクションを使用し、SSTable がこのコンパクションに含まれる場合は、時間順序を維持するために、すべての古い SSTable も含まれるようにします。
実行するコンパクションの選択
コンパクション戦略は、クエリの読み取り増幅を最小限に抑えることを目的としています。読み取り増幅は、任意のキーで重複する SSTable の数によって定義されます。コンパクションが遅い状況で最高の効率を得るために、可能な選択肢の中から重複が最も多いコンパクションバケットが選択されます。複数の選択肢がある場合は、各レベル内で均一かつランダムに 1 つを選択します。レベル間では、同じ量の作業に対してトークンスペースの大部分をカバーすることが想定されるため、最も低いレベルが優先されます。
持続的な負荷の下では、このメカニズムにより、従来の戦略では発生する可能性があった一部のレベルでの SSTable の蓄積を防ぎます。古い戦略では、すべてのリソースが L0 によって消費され、SSTable が L1 に蓄積される可能性がありました。UCS を使用すると、コンパクションが常に割り当てられたしきい値とファンファクターよりも多くの SSTable を使用する定常状態が実現し、維持できる最小の重複に基づいて階層化された階層が維持されます。
STCS および LCS との違い
階層型 UCS と従来の STCS、およびレベリング型 UCS と従来の LCS には、いくつかの違いがあることに注意してください。
階層型 UCS と STCS の比較
STCS は UCS と非常によく似ています。ただし、STCS は、サイズの事前定義されたバンディングを使用するのではなく、同じようなサイズの SSTable を探すことによってバケット/レベルを定義します。したがって、STCS は、サイズが大きく異なる SSTable にまたがる奇妙なバケットの選択になる可能性があります。UCS の選択はより安定しており、予測可能です。
STCS は、あるバケットに少なくとも min_threshold 個の SSTable が見つかったときにコンパクションをトリガーし、そのバケットから一度に min_threshold 個から max_threshold 個の SSTable をコンパクションします。min_threshold は UCS の \(t = f = w + 2\) に相当します。UCS は、非常に多数の SSTable でもコンパクションが効率的であるため、上限を削除します。
UCS は密度測定を使用して結果を分割し、SSTable のサイズとコンパクションの時間を短く抑えます。レベル内では、UCS はしきい値に達したかどうかを判断するときに重複する SSTable のみを考慮し、重複しない SSTable のセットを個別にコンパクションします。
バケット内で SSTable を選択する選択肢が複数ある場合、STCS はサイズでグループ化しますが、UCS はタイムスタンプでグループ化します。そのため、STCS は時間順序が簡単に失われ、テーブル全体の有効期限が切れにくくなります。UCS は時間順序とテーブル全体の有効期限を効率的に追跡します。UCS はテーブル全体の有効期限を適用できるため、この機能は有効期限付きの時系列データにも役立ちます。
レベリング型 UCS と LCS の比較
LCS は UCS と比較して動作が大きく異なるように見えます。ただし、実際には、2 つの戦略は非常によく似ています。
LCS はレベルごとに複数の SSTable を使用して、小さな固定サイズの重複しない SSTable のソート済み実行を形成します。そのため、増加するレベルの物理 SSTable は、サイズではなく数(fanout_size 倍)が増加します。このようにして、LCS は空間増幅を削減し、コンパクション時間を短縮します。レベルの実行の合計サイズが予想よりも大きい場合、階層の次のレベルから重複するものとコンパクションする SSTable を選択します。最終的に、次のレベルのサイズがサイズ制限を超えると、より高いレベルの操作がトリガーされます。
UCS では、増加するレベルの SSTable はファンアウトファクター \(f\) によって密度が増加します。2 番目に重複する SSTable がシャーディングされたレベルにある場合、コンパクションがトリガーされます。UCS はそのレベルで重複するバケットをコンパクションし、結果はほとんどの場合そのレベルにもなります。しかし最終的には、データは次のレベルに十分なサイズに達します。データが均等に分散されている場合、UCS と LCS は同様に動作し、コンパクションは同じタイムフレームでトリガーされます。
2 つのアプローチは非常に似た効果をもたらします。UCS には、コンパクションが他のレベルに影響を与えることができないという追加の利点があります。LCS では、L0 から L1 へのコンパクションにより、同時 L1 から L2 へのコンパクションが妨げられる可能性があり、これは unfortunate な状況です。UCS では、SSTable は階層型 UCS に簡単に切り替えたり、異なるパラメーター設定で変更したりできるように構築されています。
LCS SSTable はサイズに基づいているため分割位置が異なるため、LCS が次のレベルでコンパクションする SSTable を選択すると、部分的にのみ重複する SSTable が含まれます。その結果、SSTable は厳密に必要な回数よりも頻繁にコンパクションされる可能性があります。
UCS は、特定のトークン境界でシャーディングすることにより、空間増幅の問題に対処します。LCS は固定サイズに基づいて SSTable を分割し、境界は通常次のレベルの SSTable 内に収まるため、必要以上に頻繁にコンパクションが開始されます。したがって、UCS は厳密な書き込み増幅制御に役立ちます。これらの境界により、低密度 SSTable のスパンと正確に一致する高密度 SSTable を効率的に選択できます。
UCS オプション
| サブプロパティ | 説明 |
|---|---|
enabled |
バックグラウンドコンパクションを有効にします。 デフォルト値:true |
only_purge_repaired_tombstone |
このプロパティを有効にすると、 デフォルト値:false |
scaling_parameters |
\(L_{f}\)、\(T_{f}\)、\(N\)、または \(w\) を直接指定する整数値として指定された、レベルごとのスケーリングパラメーターのリスト。このリストの長さよりも多くのレベルが存在する場合、最後の値がすべてのより高いレベルに使用されます。多くの場合、これは単一のパラメーターであり、階層のすべてのレベルの動作を指定します。 \(L_{f}\) として指定されたレベリングコンパクションは、特にブルームフィルターが効果的でない場合(たとえば、ワイドパーティションの場合)、読み取り負荷の高いワークロードに適しています。より高いレベリングファンファクターは、書き込みコストの増加を犠牲にして、読み取り増幅(したがって、レイテンシと読み取り主体のワークロードのスループット)を向上させます。従来の LCS に相当するのは L10 です。 \(T_{f}\) として指定された階層型コンパクションは、書き込み負荷の高いワークロード、またはブルームフィルターや時間順序を利用できるワークロードに適しています。より高い階層型ファンファクターは、書き込みコスト(したがってスループット)を向上させますが、読み取りがより困難になるという犠牲を払います。 \(N\) は、レベリング(レベルごとに1つのSSTableラン)と階層化(次のレベルに昇格される1つのコンパクション)の両方の機能と、ファンアウト係数2を備えた中間的な設定です。この値は、T2またはL2として指定することもできます。 デフォルト値:T4(しきい値4のSTCS) |
target_sstable_size |
ターゲットSSTableサイズ \(s_{t}\) は、MiB などの、人間が理解しやすいバイト単位のサイズで指定します。この戦略では、\(s_{t}/\sqrt{2}\) から \(s_{t} \cdot \sqrt{2}\) の間のサイズのSSTableを生成することを目指して、データをシャードに分割します。SSTableが小さいほど、ストリーミングとリペアが改善され、コンパクションが短縮されます。一方、ディスク上の各SSTableは、ガベージコレクション時間にも影響を与える、無視できないインメモリフットプリントを持っています。システム内のSSTableの数によるメモリプレッシャーが高すぎる場合は、この値を増やしてください。 デフォルト:1 GiB |
min_sstable_size |
最小SSTableサイズ。ベースシャード数によって生成されるSSTableが小さすぎるとみなされる場合に適用されます。設定されている場合、この戦略は、推定されるSSTableサイズがこの値以上になるように、スペースをベース数よりも少ないシャードに分割します。値0はこの機能を無効にします。 デフォルト:100MiB |
base_shard_count |
最小シャード数 \(b\)。密度が最も低いレベルで使用されます。これは、最下位レベルの最小コンパクション並行性を示します。数が少ないと、L0 SSTableが大きくなりますが、全体的な最大書き込みスループットが制限される可能性があります(すべてのデータがL0を通過する必要があるため)。 デフォルト:4(システムテーブルの場合、または複数のデータロケーションが定義されている場合は1) |
sstable_growth |
SSTable成長成分 \(\lambda\)。シャード指数計算の係数として適用されます。これは、0から1の間の数値で、密度増加のどの部分が個々のSSTableサイズに適用され、どの部分がシャード数の増加に適用されるかを制御します。値1を使用すると、シャード数がベース値に固定されます。0.5を使用すると、シャード数とSSTableサイズが密度増加の平方根とともに増加します。これは、非常に大きなデータセットに対して作成されるSSTableの数を減らすのに役立ちます。たとえば、増加補正を行わない場合、1GiBのターゲットサイズを持つ10TiBのデータセットは、10Kを超えるSSTableになります。これほど多くのSSTableは、SSTableごとの構造で使用されるヒープメモリと、コンパクション中のSSTableの交差と重複セットの追跡の両方で、オーバーヘッドが多すぎる可能性があります。たとえば、ベースシャード数が4の場合、成長係数により、潜在的なSSTableの数をメモリオーバーヘッド、個々のコンパクション期間、およびスペースオーバーヘッドの点で管理可能な約64GiBの約160に減らすことができます。パラメータを調整して、値を大きくするとトップレベルのSSTableの数が少なくなり、大きくなります。値を小さくすると、小さいSSTableの数が多くなります。 デフォルト:0.333(SSTableサイズはシャード数の増加の平方根とともに増加します) |
expired_sstable_check_frequency_seconds |
期限切れのSSTableをチェックする頻度を決定します。 デフォルト:10分 |
max_sstables_to_compact |
1回の操作でコンパクションするSSTableの最大数。値を大きくすると書き込み増幅が減少しますが、非常に長いコンパクションが発生する可能性があり、そのため、そのようなコンパクションの処理中に非常に高い読み取り増幅オーバーヘッドが発生する可能性があります。デフォルトでは、操作の長さを制御し、コンパクションの実行中にSSTableが蓄積されないようにすることを目的としています。ファンアウト係数がSSTableの最大数よりも大きい場合、この戦略は後者を無視します。 デフォルト:なし(ただし、32が良い選択です) |
overlap_inclusion_method |
重複するセクションをバケットにどのように拡張するかを指定します。TRANSITIVEは、コンパクションするSSTableを選択した場合、それと重複するSSTableもコンパクションするようにします。SINGLEはこの拡張を1回だけ行います(つまり、元の重複するSSTableセクションと重複するSSTableのみを選択します)。NONEは重複するSSTableを追加しません。NONEは推奨されません。SINGLEは、LCSからアップグレードする場合、または範囲の移動中に一部のデータを再コンパクションするという犠牲を払って、もう少し並列処理を提供する可能性があります。 デフォルト:TRANSITIVE |
unsafe_aggressive_sstable_expiration |
期限切れのSSTableは、そのデータが他のSSTableをシャドウイングしているかどうかを確認せずに削除されます。このフラグは、`cassandra.allow_unsafe_aggressive_sstable_expiration` がtrueの場合にのみ有効にできます。このフラグをオンにすると、削除されたデータの再出現など、正確性の問題が発生する可能性があります。有効なユースケースと潜在的な問題については、CASSANDRA-13418 の議論を参照してください。 デフォルト:false |
`cassandra.yaml` には、コンパクションに影響を与えるパラメータが1つあります
- concurrent_compactors
-
アンチエントロピーリペアのための検証「コンパクション」を含まない、許可する同時コンパクションの数。値を大きくするとコンパクションのパフォーマンスは向上しますが、読み取りと書き込みのレイテンシが増加する可能性があります。