Apache Cassandra とは?
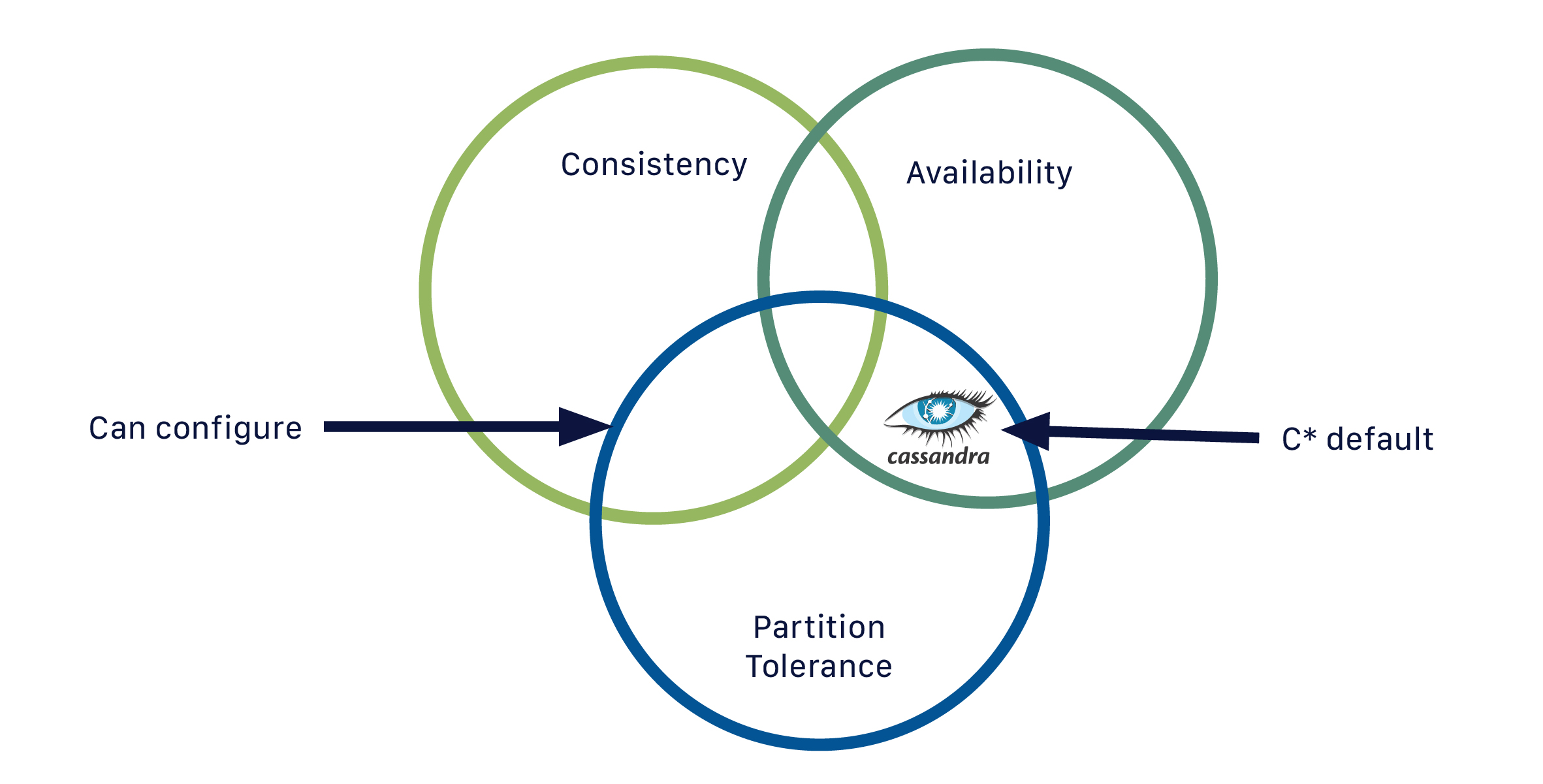
CassandraはNoSQL分散データベースです。NoSQLデータベースは、設計上、軽量で、オープンソース、非リレーショナル、そして大規模に分散されています。その強みとして、水平スケーラビリティ、分散アーキテクチャ、スキーマ定義の柔軟なアプローチが挙げられます。
NoSQLデータベースは、非常に大量で異種なデータタイプを迅速かつアドホックに組織化および分析することを可能にします。ビッグデータの出現とクラウドにおけるデータベースの迅速なスケーリングの必要性が高まっている近年、これはますます重要になっています。Cassandraは、SQLデータベースなどの従来のデータ管理技術の制約に対処してきたNoSQLデータベースの一つです。
分散化によるパワーとレジリエンス
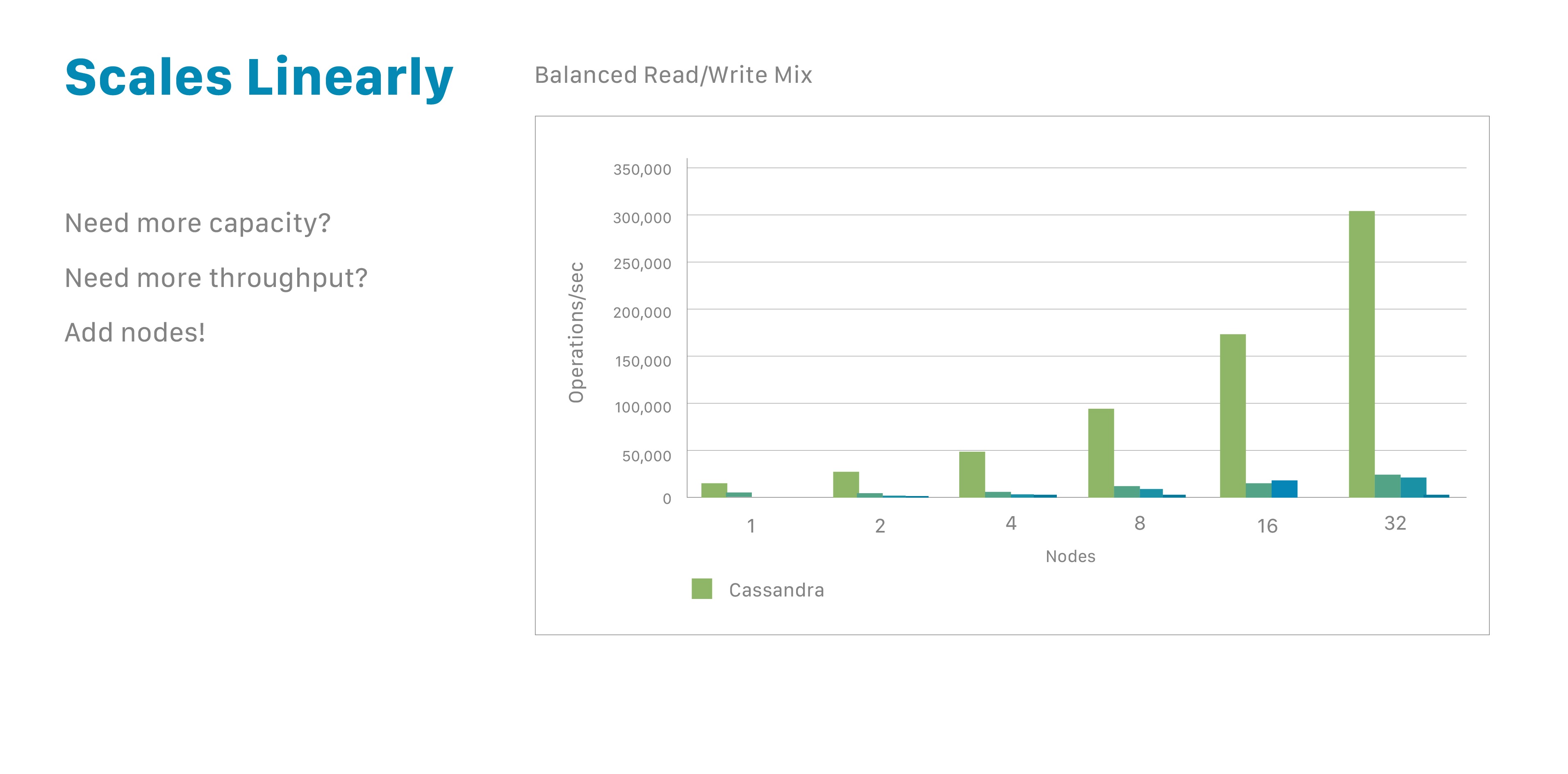
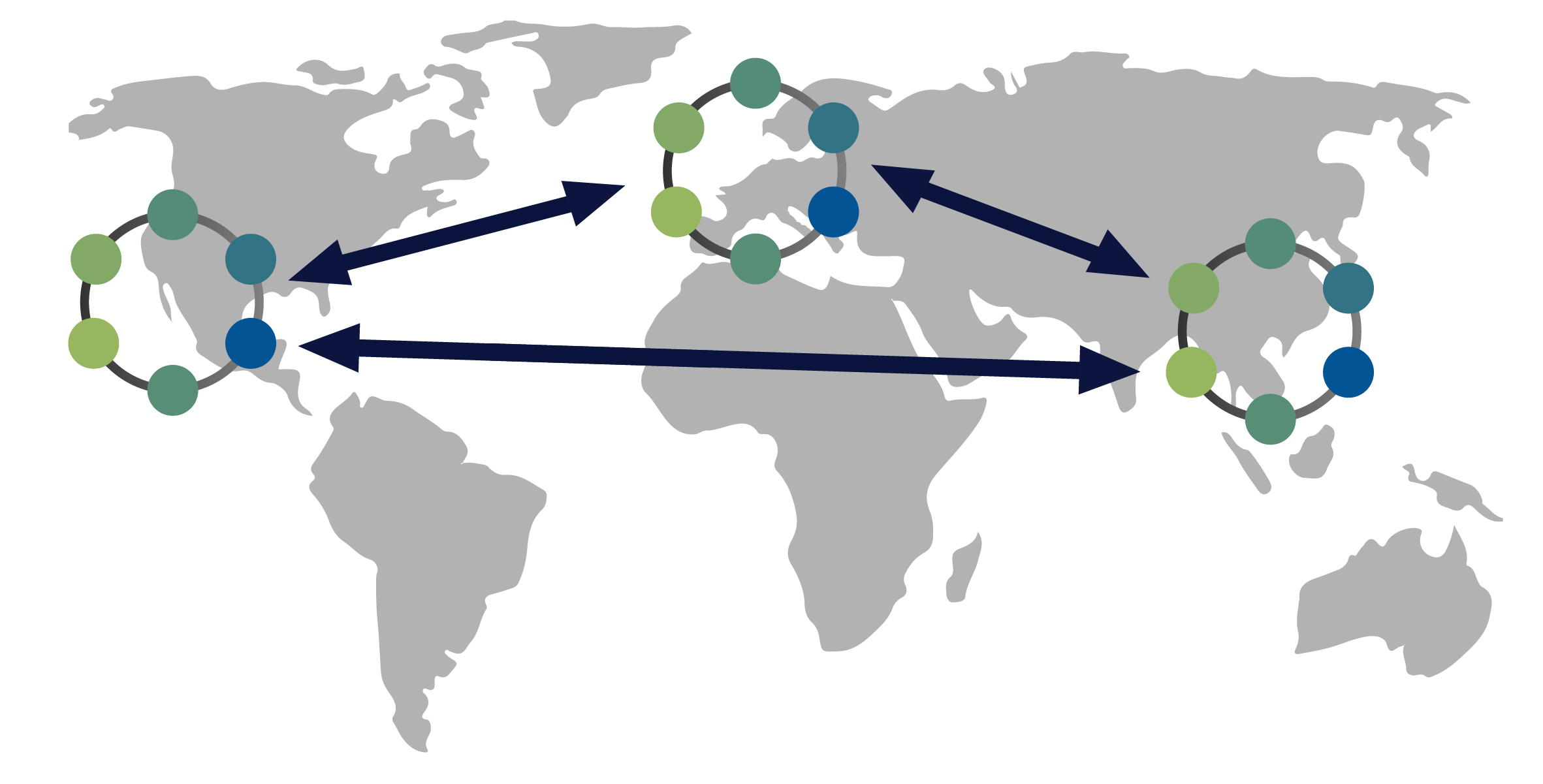
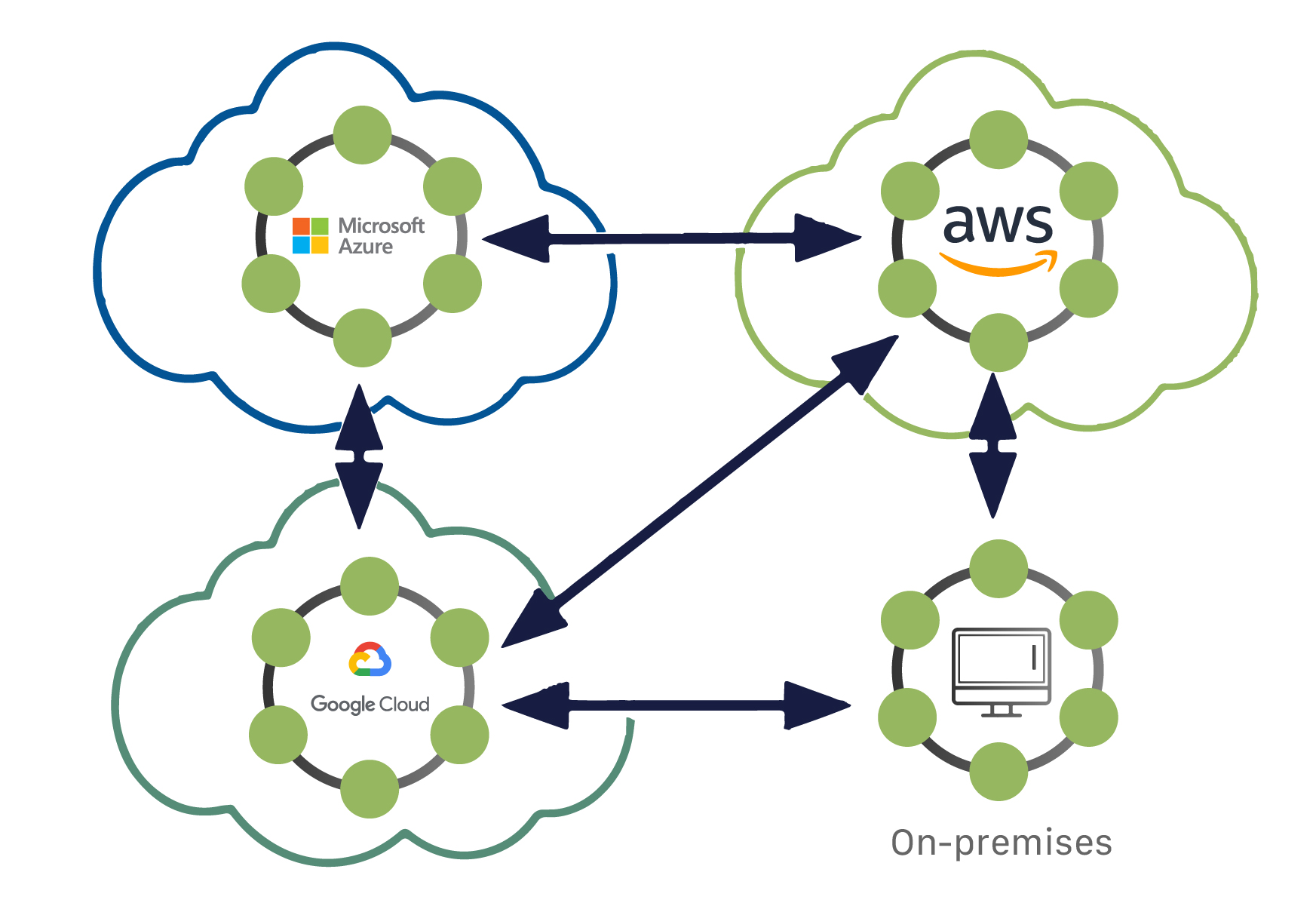
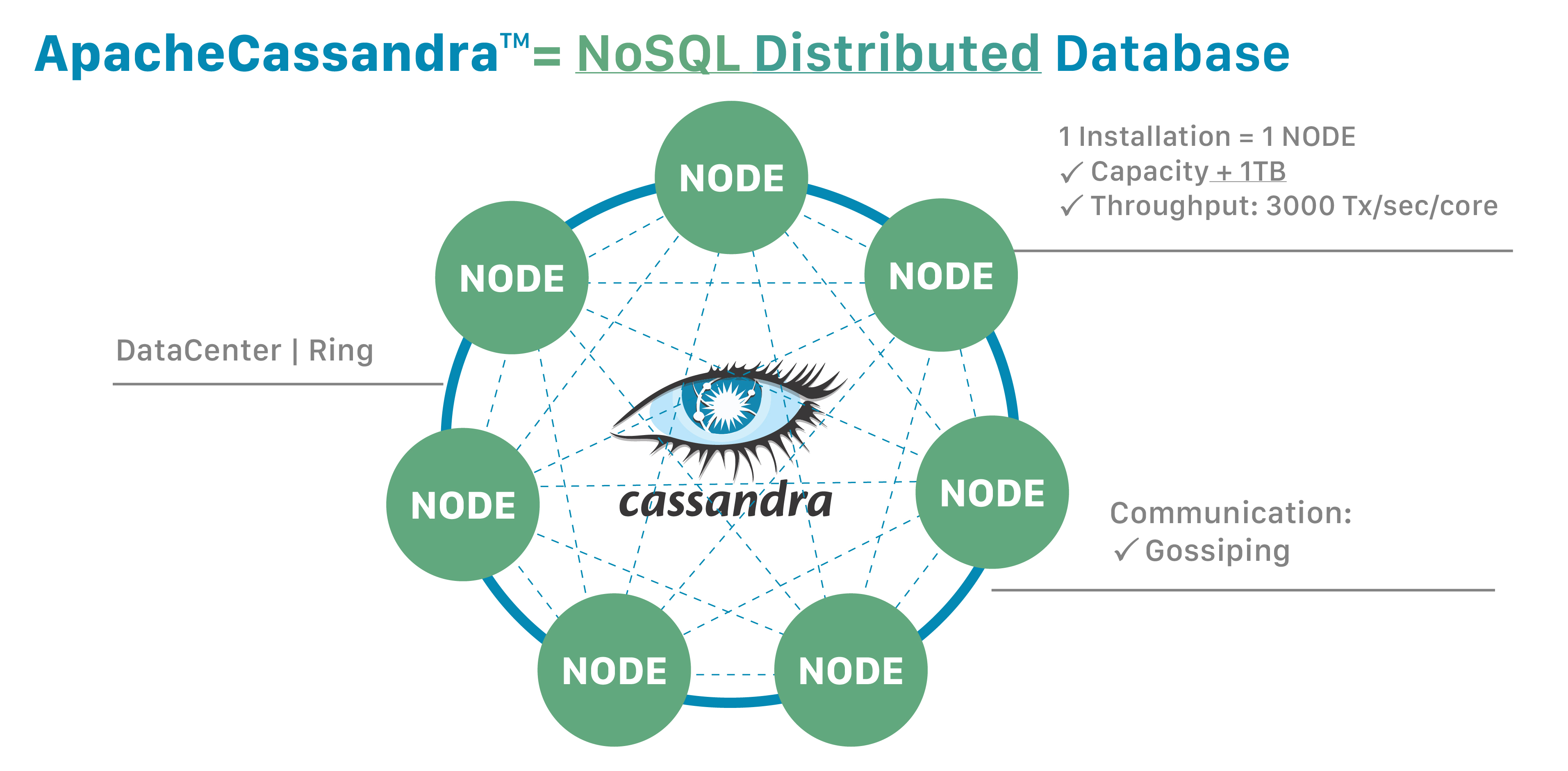 Cassandraの重要な属性の一つは、そのデータベースが分散されていることです。これにより、技術的な利点とビジネス上の利点の両方がもたらされます。Cassandraデータベースは、アプリケーションが高負荷状態にある場合でも容易にスケールし、分散化によって特定のデータセンターのハードウェア障害によるデータ損失を防ぎます。分散アーキテクチャは技術的なパワーも提供します。例えば、開発者は読み取りクエリまたは書き込みクエリのスループットを個別に調整できます。
Cassandraの重要な属性の一つは、そのデータベースが分散されていることです。これにより、技術的な利点とビジネス上の利点の両方がもたらされます。Cassandraデータベースは、アプリケーションが高負荷状態にある場合でも容易にスケールし、分散化によって特定のデータセンターのハードウェア障害によるデータ損失を防ぎます。分散アーキテクチャは技術的なパワーも提供します。例えば、開発者は読み取りクエリまたは書き込みクエリのスループットを個別に調整できます。
「分散」とは、Cassandraが複数のマシン上で動作しながら、ユーザーには統合された全体として表示されることを意味します。Cassandraを単一ノードで実行することにはほとんど意味がありませんが、動作方法を理解するために単一ノードで実行することは非常に役立ちます。しかし、Cassandraを最大限に活用するには、複数のマシンで実行する必要があります。
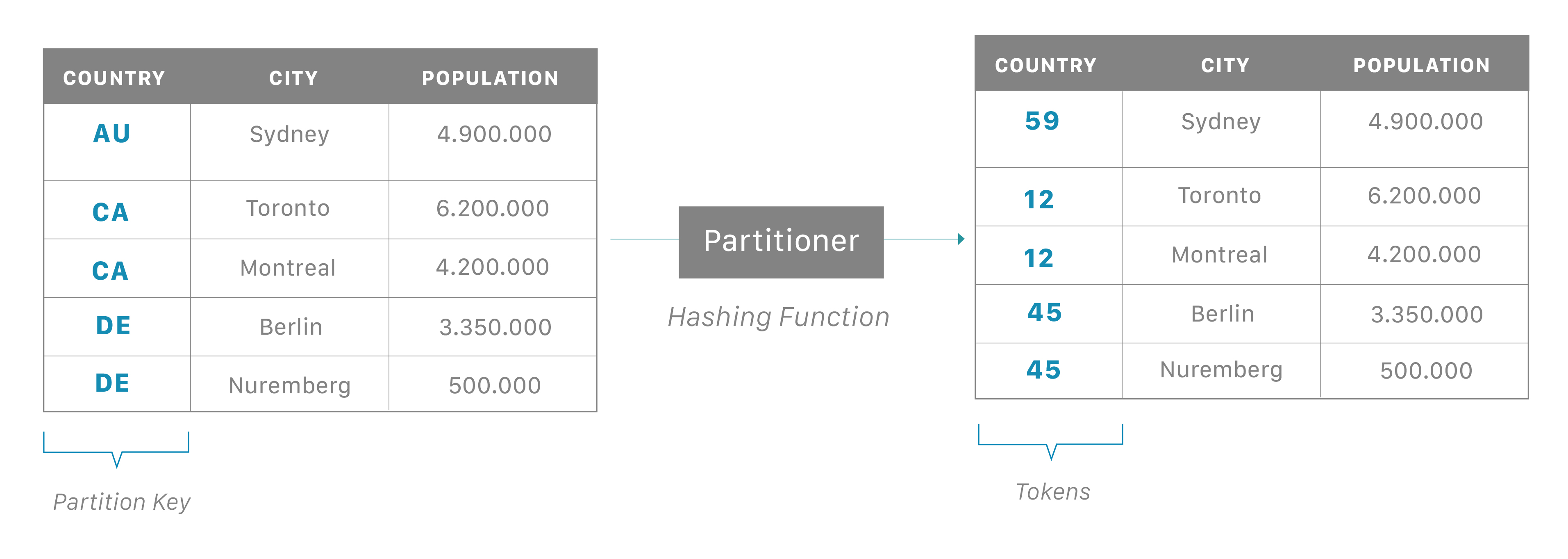
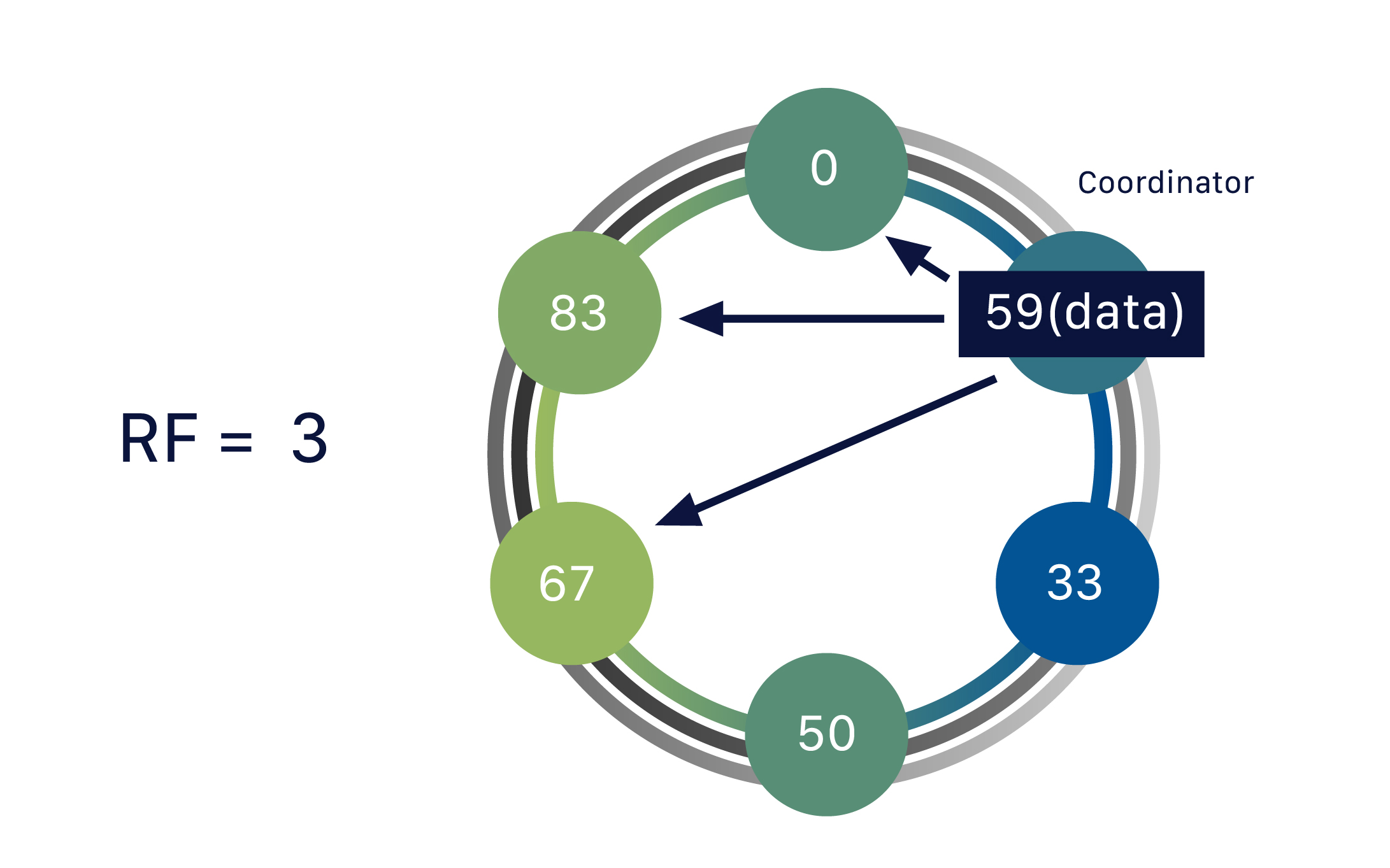
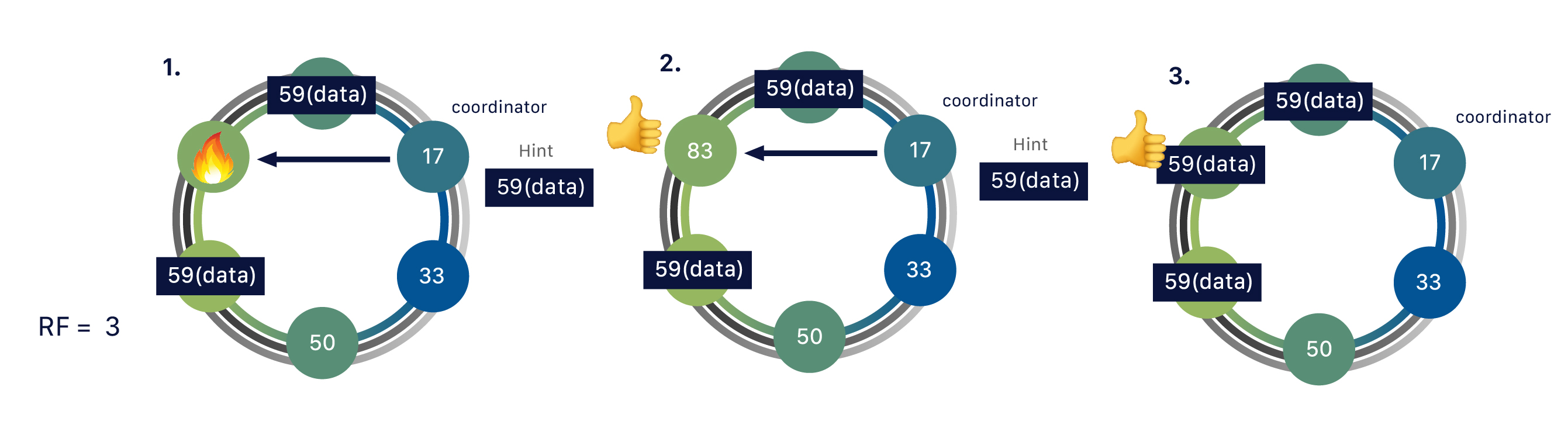
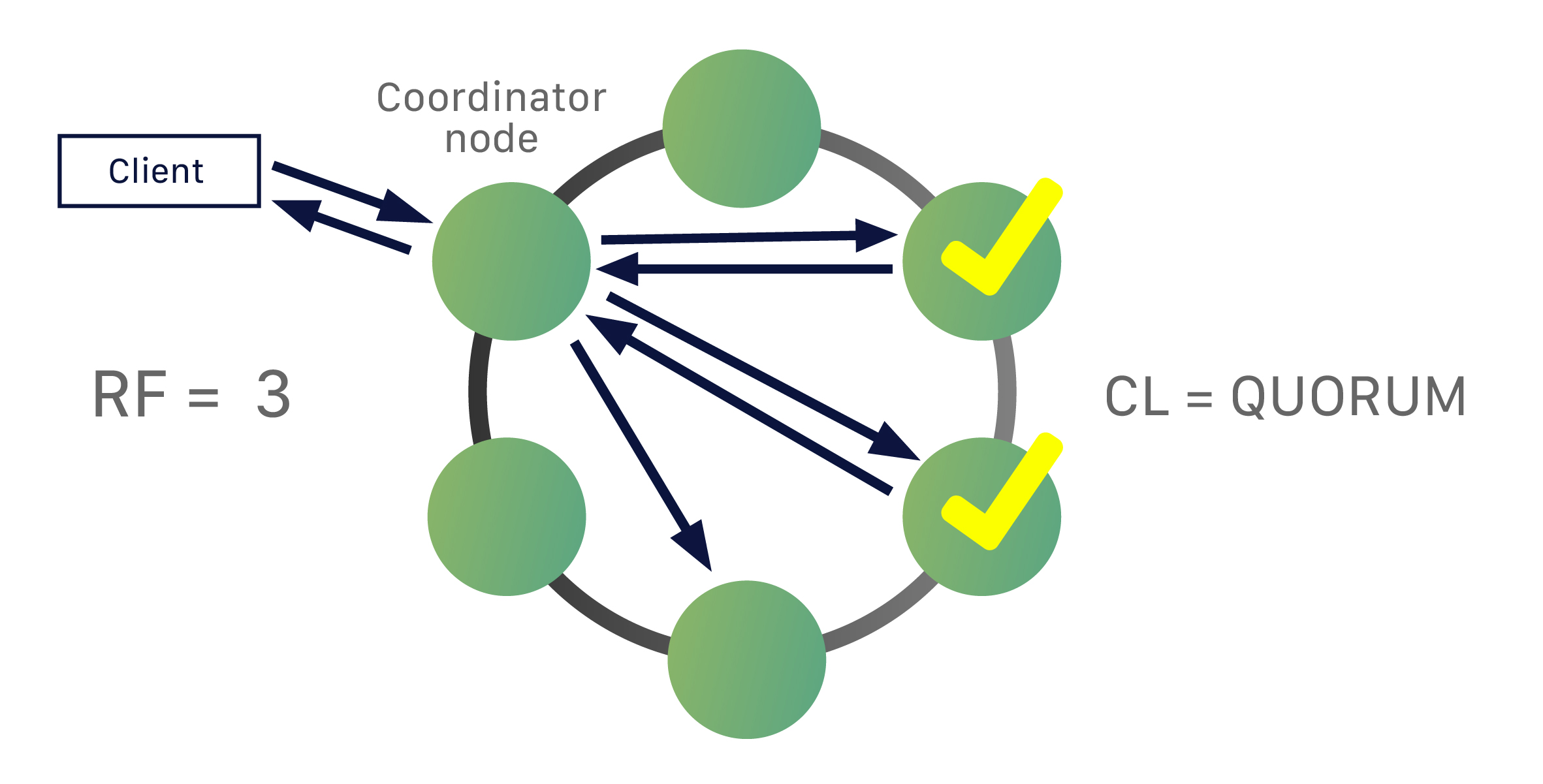
分散データベースであるため、Cassandraは(通常は)複数のノードを持つことができます。ノードは、Cassandraの単一インスタンスを表します。これらのノードは、ゴシップと呼ばれるピアツーピア通信のプロセスを通じて互いに通信します。Cassandraはマスターレスアーキテクチャも採用しています。データベース内のどのノードも、他のノードと同じ機能を提供できます。これにより、Cassandraの堅牢性とレジリエンスが向上します。複数のノードは、論理的にクラスタまたは「リング」に編成できます。複数のデータセンターを持つことも可能です。