













はじめに
Apache Cassandra はデータをテーブルに格納します。各テーブルは行と列で構成されます。CQL(Cassandra Query Language)は、テーブルに格納されているデータをクエリするために使用されます。Apache Cassandra データモデルは、クエリを中心に構築され、最適化されています。Cassandra は、リレーショナルデータベース向けのデータモデリングをサポートしていません。
データモデリングとは?
データモデリングとは、エンティティとその関係を特定するプロセスです。リレーショナルデータベースでは、データは正規化されたテーブルに配置され、外部キーを使用して他のテーブルの関連データを参照します。アプリケーションが行うクエリはテーブルの構造によって決まり、関連データはテーブル結合としてクエリされます。
Cassandra では、データモデリングはクエリ駆動型です。データアクセスパターンとアプリケーションクエリが、データベーステーブルの設計に使用されるデータの構造と編成を決定します。
データは特定のクエリを中心にモデル化されます。クエリは単一のテーブルにアクセスするように設計するのが最適です。これは、クエリに関連するすべてのエンティティが同じテーブルに存在して、データアクセス(読み取り)を非常に高速にする必要があることを意味します。データは、クエリまたはクエリのセットに最適なようにモデル化されます。テーブルには、クエリに最適なように、1 つ以上のエンティティを含めることができます。エンティティは通常、それらの間に関係を持っており、クエリはそれらの間に関係を持つエンティティを含む可能性があるため、単一のエンティティが複数のテーブルに含まれる場合があります。
クエリ駆動型モデリング
クエリがテーブル結合を使用して複数のテーブルからデータを取得するリレーショナルデータベースモデルとは異なり、Cassandra では結合がサポートされていないため、必要なすべてのフィールド(列)を単一のテーブルにグループ化する必要があります。各クエリはテーブルによって裏付けられているため、データは非正規化と呼ばれるプロセスで複数のテーブルに複製されます。データの複製と高い書き込みスループットを使用して、高い読み取りパフォーマンスを実現します。
目標
プライマリキーとパーティションキーの選択は、データをクラスター全体に均等に分散するために重要です。クエリの読み取りパーティション数を最小限に抑えることも重要です。これは、異なるパーティションが異なるノードに配置される可能性があり、コーディネーターが各ノードにリクエストを送信する必要があるため、リクエストのオーバーヘッドとレイテンシが増加するためです。クエリの異なるパーティションが同じノードにある場合でも、パーティションが少ないほどクエリが効率的になります。
パーティション
Apache Cassandra は、ノードのクラスター全体にデータを格納する分散データベースです。パーティションキーは、ノード間でデータをパーティション化するために使用されます。Cassandra は、データ分散のための一貫性ハッシュのバリアントを使用して、ストレージノードにデータをパーティション化します。ハッシュとは、キーが与えられると、ハッシュ関数がハッシュテーブルに格納されるハッシュ値(または単にハッシュ)を生成するデータとマップするために使用される手法です。パーティションキーは、プライマリキーの最初のフィールドから生成されます。パーティションキーを使用してハッシュテーブルにパーティション化されたデータは、高速なルックアップを提供します。クエリに使用されるパーティションが少ないほど、クエリの応答時間は短くなります。
パーティションの例として、`id` がプライマリキーの唯一のフィールドであるテーブル `t` を考えてみます。
CREATE TABLE t ( id int, k int, v text, PRIMARY KEY (id) );
パーティションキーは、クラスター内のノード全体にデータを分散するために、プライマリキー `id` から生成されます。
プライマリキーを構成する 2 つのフィールドを持つテーブル `t` のバリエーションを考えてみましょう。これにより、複合プライマリキーが作成されます。
CREATE TABLE t ( id int, c text, k int, v text, PRIMARY KEY (id,c) );
複合プライマリキーを持つテーブル `t` の場合、最初のフィールド `id` はパーティションキーの生成に使用され、2 番目のフィールド `c` はパーティション内でのソートに使用されるクラスタリングキーです。クラスタリングキーを使用してデータをソートすると、隣接データの取得がより効率的になります。
一般に、プライマリキーの最初のフィールドまたはコンポーネントはハッシュ化されてパーティションキーが生成され、残りのフィールドまたはコンポーネントはパーティション内でデータをソートするために使用されるクラスタリングキーです。データをパーティション化すると、読み取りと書き込みの効率が向上します。プライマリキーフィールドではない他のフィールドは、クエリのパフォーマンスをさらに向上させるために個別にインデックス化できます。
プライマリキーの最初のコンポーネントとしてグループ化されている場合、パーティションキーは複数のフィールドから生成できます。テーブル `t` の別のバリエーションとして、プライマリキーの最初のコンポーネントが括弧を使用してグループ化された 2 つのフィールドで構成されているテーブルを考えてみます。
CREATE TABLE t ( id1 int, id2 int, c1 text, c2 text k int, v text, PRIMARY KEY ((id1,id2),c1,c2) );
上記のテーブル `t` の場合、フィールド `id1` と `id2` で構成されるプライマリキーの最初のコンポーネントはパーティションキーの生成に使用され、残りのフィールド `c1` と `c2` はパーティション内でのソートに使用されるクラスタリングキーです。
リレーショナルデータモデルとの比較
リレーショナルデータベースは、外部キーを使用して他のテーブルとの関係を持つテーブルにデータを格納します。リレーショナルデータベースのデータモデリングへのアプローチは、テーブル中心です。クエリは、テーブル結合を使用して、それらの間に関係を持つ複数のテーブルからデータを取得する必要があります。Apache Cassandra には、外部キーまたはリレーショナル整合性の概念がありません。Apache Cassandra のデータモデルは、複数のテーブルを含まない効率的なクエリを設計することを中心に構築されています。リレーショナルデータベースは、重複を避けるためにデータを正規化します。対照的に、Apache Cassandra は、クエリ中心のデータモデルのために複数のテーブルにデータを複製することによってデータを非正規化します。Cassandra データモデルが特定のクエリの異なるエンティティ間の関係の複雑さを完全に統合できない場合は、アプリケーションコードのクライアント側結合を使用できます。
データモデリングの例
例として、`magazine` データセットは、雑誌 ID、雑誌名、発行頻度、発行日、発行者などの属性を持つ雑誌のデータで構成されています。雑誌データの基本的なクエリ(Q1)は、発行頻度を含むすべての雑誌名をリストすることです。Q1 にはすべてのデータ属性が必要なわけではないため、データモデルは図 1 に示すように、`id`(パーティションキー用)、雑誌名、発行頻度のみで構成されます。
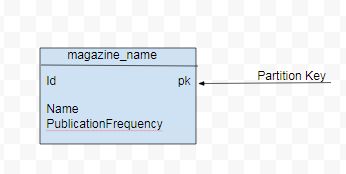
別のクエリ(Q2)は、発行者別にすべての雑誌名をリストすることです。Q2 の場合、データモデルはパーティションキーに追加の属性 `publisher` で構成されます。`id` は、パーティション内でのソートのクラスタリングキーになります。Q2 のデータモデルを図 2 に示します。

スキーマの設計
概念データモデルを作成した後、クエリ用にスキーマを設計できます。Q1 の場合、次のスキーマを使用できます。
CREATE TABLE magazine_name (id int PRIMARY KEY, name text, publicationFrequency text)Q2 の場合、スキーマ定義にはソート用のクラスタリングキーが含まれます。
CREATE TABLE magazine_publisher (publisher text,id int,name text, publicationFrequency text,
PRIMARY KEY (publisher, id)) WITH CLUSTERING ORDER BY (id DESC)データモデル分析
データモデルは、ストレージ、容量、冗長性、および整合性に基づいて分析および最適化する必要がある概念モデルです。分析の結果として、データモデルを変更する必要がある場合があります。データモデル分析で使用される考慮事項または制限事項には、次のものがあります。
-
パーティションサイズ
-
データ冗長性
-
ディスク容量
-
軽量トランザクション (LWT)
パーティションサイズの 2 つの尺度は、パーティション内の値の数とディスク上のパーティションサイズです。これらのメジャーの要件はアプリケーションによって異なる場合がありますが、一般的なガイドラインとして、パーティションあたりの値の数を 100,000 未満、パーティションあたりのディスク容量を 100MB 未満に保つことです。
テーブル内の重複データや複数のパーティションレプリケートなどのデータ冗長性は、データモデルの設計で予想されますが、それでも最小限に抑えるパラメータとして考慮する必要があります。LWT トランザクション(比較と設定、条件付き更新)はパフォーマンスに影響を与える可能性があり、LWT を使用するクエリは最小限に抑える必要があります。