













SAIの書き込みパスと読み取りパス
SAIは、基盤となるデータベースのストレージエンジンと深く統合されています。SAIはテーブルを抽象的にインデックス化するのではなく、書き込まれるときにMemtableとSorted String Table(SSTable)をインデックス化し、読み取り時にこれらのインデックスの違いを解決します。各Memtableは、特定のデータベーステーブルに固有のインメモリデータ構造です。Memtableはライトバックキャッシュに似ています。各SSTableは、データベースが定期的にMemtableを書き込む不変のデータファイルです。SSTableはディスクに順番に保存され、各データベーステーブルに対して保持されます。
このトピックでは、SAIの読み取りパスと書き込みパスの詳細について説明し、SAIインデックスのライフサイクルを調べます。
SAIの書き込みパス
SAIインデックスは、CQLテーブルにデータが書き込まれる前、またはデータが書き込まれた後に作成できます。復習として、CQLテーブルに書き込まれたデータは、最初にMemtableに書き込まれ、次にMemtableからデータがフラッシュされるとSSTableに書き込まれます。SAIインデックスが作成された後、SAIは現在のMemtableに対するすべての変更を通知されます。他のデータと同様に、SAIは挿入と更新のインデックスを更新します。Apache Cassandraはこれらをまったく同じように扱います。SAIは、パーティションの削除、範囲トームストーン、および行の削除もサポートしています。クエリで削除操作が実行されると、SAIはポストフィルタリングステップでインデックスの変更を処理します。その結果、SAIは頻繁に削除される列をインデックス化するときに特別なペナルティを課しません。
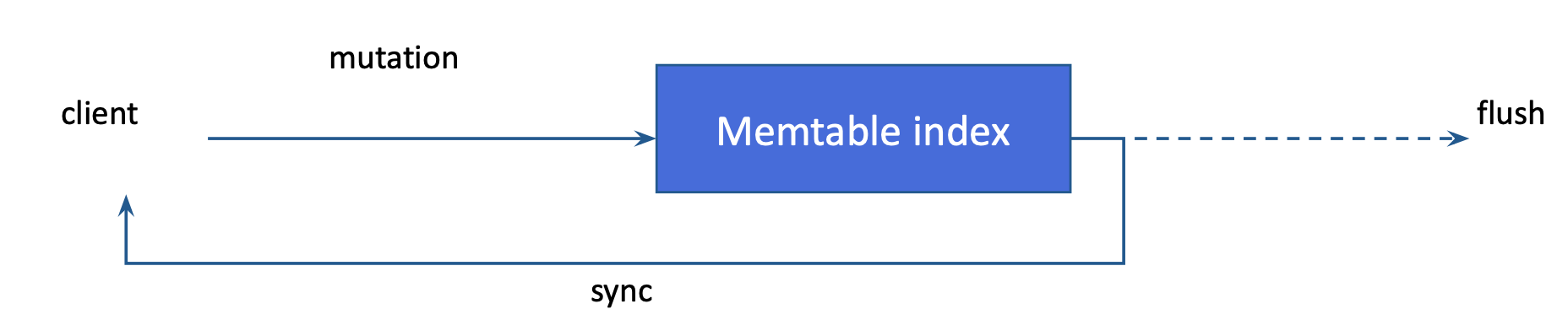
挿入または更新にインデックス付き列の有効なコンテンツが含まれている場合、コンテンツはMemtableインデックスに追加され、更新された行のプライマリキーがインデックス付きの値に関連付けられます。SAIは、新しいエントリのインクリメンタルヒープ消費量の見積もりを計算します。この見積もりは、基盤となるMemtableのヒープ使用量に影響します。この機能は、テーブルにインデックスが付けられる列が増えるほど、Memtableのフラッシュ率が向上し、フラッシュされたSSTableのサイズが小さくなることも意味します。すべてのライブMemtableインデックスの合計書き込み数と推定ヒープ使用量は、メトリクスとして公開されます。「SAIメトリクス」を参照してください。
Memtableのフラッシュ
SAIは、追加のインメモリ表現を作成するのではなく、フラッシュしきい値に達すると、Memtableインデックスの内容を直接ディスクにフラッシュします。これは、Memtableインデックスが項/値でソートされ、次にプライマリキーでソートされるため可能です。フラッシュが発生すると、SAIは、SSTableが書き込まれているときに、インデックス付き列ごとに新しいSSTableインデックスを書き込みます。
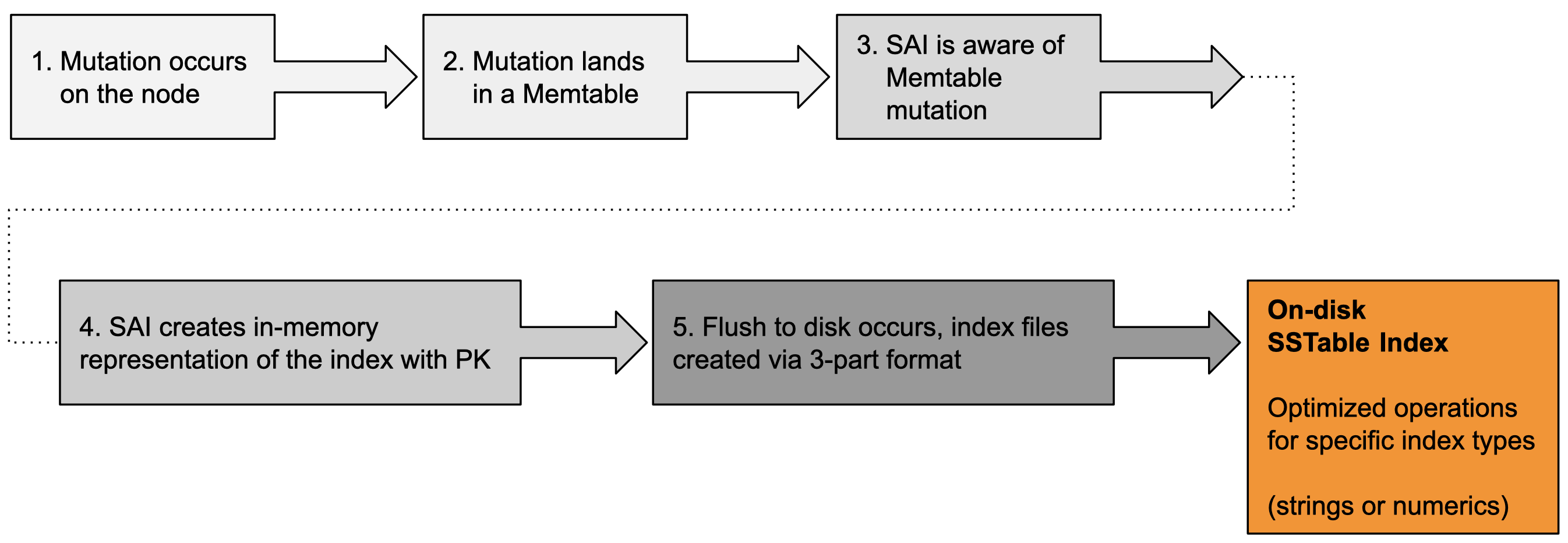
フラッシュ操作は2段階のプロセスです。最初のフェーズでは、行が新しいSSTableに書き込まれます。行ごとに、行IDが生成され、3つのインデックスコンポーネントが作成されます。コンポーネントは
-
行IDから対応するトークン値へのディスク上マッピング—SAIはMurmur3Partitionerをサポートしています
-
SSTableパーティションオフセット
-
プライマリキーから行IDへの一時的なマッピング。これは、後続のフェーズで使用されます。
最初のコンポーネントファイルと2番目のコンポーネントファイルの内容は、順序が行IDに対応する圧縮された配列です。
2番目のフェーズでは、すべての行が新しいSSTableに書き込まれ、共有SSTableレベルのインデックスコンポーネントが完了した後、SAIはインデックス付きの各列でインデックス作成作業を開始します。具体的には、2番目のフェーズでは、SAIはMemtableインデックスを反復処理して、項のペアとそれらのトークンソートされた行IDを生成します。このイテレータは、最初のフェーズで構築された一時的なマッピング構造を使用して、プライマリキーを行IDに変換します。次に、項イテレータ(ポスティング付き)は、インデックス付き要素が文字列または数値列のどちらであるかに基づいて、個別の書き込みコンポーネントに渡されます。
文字列の場合、SAIインデックスライターは各項を反復処理し、最初にポスティングをディスクに書き込み、次にポスティングファイルのオフセットを、ディスク上のバイト順トライのエントリ(項自体の場合)のペイロードとして記録します。数値の場合、SAIは数値インデックスの書き込みを2つのステップに分けます
項は、kd-treeをディスクに書き込むバランスの取れたkd-treeライターに渡されます。ツリーのリーフブロックが書き込まれると、それらのポスティングがメモリに一時的に記録されます。次に、それらの一時的なポスティングを使用して、リーフ、およびインデックスノードのさまざまなレベルで、ディスク上のポスティングを構築します。
列インデックスのフラッシュが完了すると、特別な空のマーカーファイルが成功を示すためにフラグ設定されます。この手順は、起動時および増分再構築操作で、次のような場合を区別するために使用されます。
-
列のSSTableインデックスファイルがありません。
-
インデックス可能なデータはありません。たとえば、SSTableにトームストーンのみが含まれている場合などです。(トームストーンは、列が削除されたことを示す行内のマーカーです。コンパクション中に、マークされた列は削除されます。)
次に、SAIは列に対してフラッシュされたMemtableインデックスの数をインクリメントし、1秒あたりにフラッシュされたセルの数をヒストグラムに追加します。
コンパクションがトリガーされたとき
Apache Cassandraはコンパクションを使用してSSTableをマージすることを思い出してください。コンパクションは、各一意の行のすべてのバージョンを収集し、SSTableからの各行の列の最新バージョン(タイムスタンプによる)を使用して、1つの完全な行をアセンブルします。マージプロセスは、各SSTable内で行がパーティションキーでソートされ、マージプロセスがランダムI/Oを使用しないため、パフォーマンスが高くなります。各行の新しいバージョンは、新しいSSTableに書き込まれます。古いバージョンは、削除の準備ができている行とともに、古いSSTableに残され、保留中の読み取りが完了すると削除されます。

SAIの場合、コンパクションがトリガーされると、各インデックスグループはSSTable Flush Observerを作成して、それぞれのSSTableライターインスタンスで新しくコンパクションされたデータから、添付されたすべての列インデックスを書き込むプロセスを調整します。(インデックス付きの用語がすでにソートされているMemtableフラッシュとは異なり)コンパクション中にマージされたデータを反復処理する場合、SAIはインデックス付きの値とその行IDをバッファリングします。これらはトークン順に追加されます。
利用可能なヒープリソースの枯渇などの問題を回避するために、SAIは、独自の計算を使用して同期的にディスクにフラッシュされる累積セグメントバッファを使用します。次に、各セグメントはセグメント行IDのオフセットを記録し、セグメント行IDのみを保存します(SSTable行IDからセグメント行IDオフセットを引いたもの)。SAIは、すべてのセグメントを書き換えるコストを回避し、パーティション制限付きクエリとページング範囲クエリのコストを削減するために、同じファイルにセグメントを同期的にフラッシュします。これにより、検索スペースが削減されます。
列ごとのインデックス付きポスティングから、SSTableオフセット、SSTableパーティションへのディスク上のレイアウト
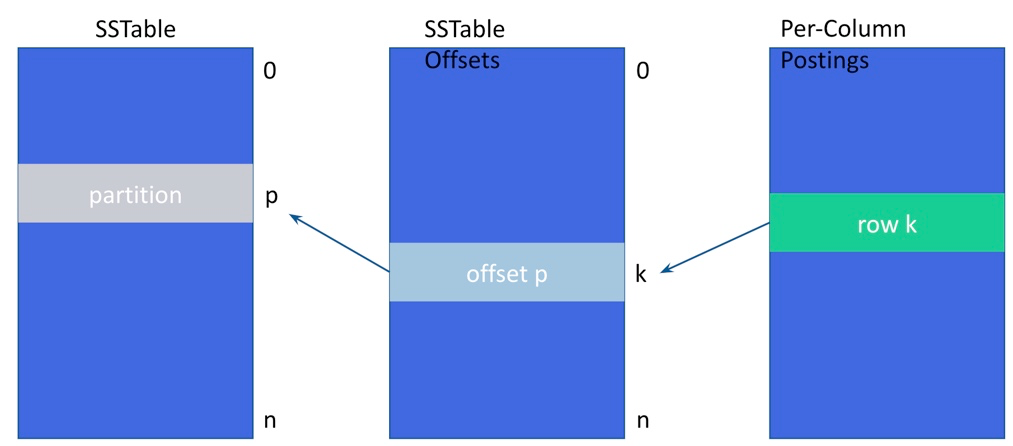
実際のセグメントフラッシュプロセスは、Memtableフラッシュと非常によく似ています。ただし、バッファリングされた用語は、ポスティングとともにそれぞれのタイプ固有のディスク上構造に書き込むことができる前にソートされます。特定のインデックスのコンパクションの最後に、特別な空のマーカーファイルに成功を示すためにフラグが設定され、セグメントの数がSAIメトリクスに記録されます。「グローバルインデックスメトリクス」を参照してください。
コンパクションタスク全体が終了すると、SAIは、トランザクション中に追加および削除されたSSTableを含むSSTableリスト変更通知を受信します。SSTableコンテキストマネージャーとインデックスビューマネージャーは、古いSSTableインデックスを新しいものとアトミックに置き換える役割を担います。この時点で、新しいSSTableインデックスをクエリに使用できるようになります。
SAIの読み取りパス
このセクションでは、SAIコーディネーターがインデックスクエリをどのように処理し、レプリカによってどのように実行されるかを説明します。レガシーセカンダリインデックスでは、クエリごとに最大1つの列インデックスが使用されますが、SAIは、単一のクエリですべての利用可能な列インデックスを使用できるようにするクエリプランを実装します。
SAI読み取り操作の全体的な流れは次のとおりです
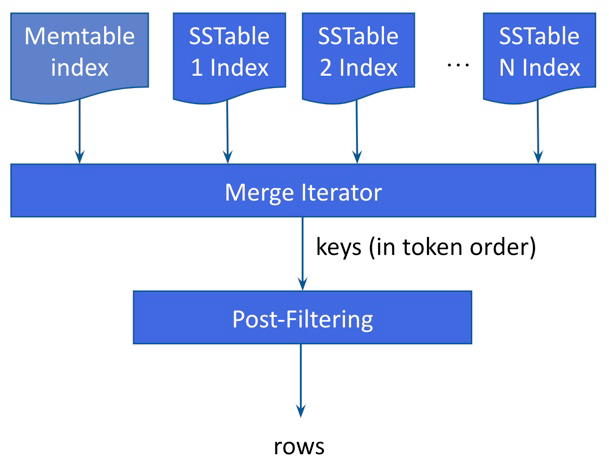
インデックス選択とコーディネーター処理
クエリが提示されると、SAIコーディネーターが1つ以上のインデックスを利用するために実行する最初のアクションは、最も選択的なインデックスを識別することです。最も選択的なインデックスとは、推定結果行の計算から最も低い値を返すことによって、フィルタリングスペースと最終的な結果の数を最も積極的に絞り込むインデックスです。複数のSAIインデックスが存在する場合(つまり、各SAIインデックスが異なる列に基づいており、クエリに複数の列が含まれている場合)、最初に選択されるSAIインデックスは関係ありません。
読み取り操作に最適なインデックスが選択されると、そのインデックスは読み取りコマンドに埋め込まれ、分散レンジ読み取り装置に入ります。分散レンジ読み取りは、トークン順に1回以上のラウンドでApache Cassandraクラスタをクエリします。SAIコーディネーターは、ローカルデータとクエリ制限に基づいて、並行処理係数、つまりレンジあたりの行数を推定し、問い合わせるレンジ数を決定します。各ラウンドで、並行処理係数によって、並列でクエリされるレプリカの数が決まります。
最初のラウンドが開始される前に、SAIは独自の計算(ここではステップ1として示されています)によって初期並行処理係数を推定します。
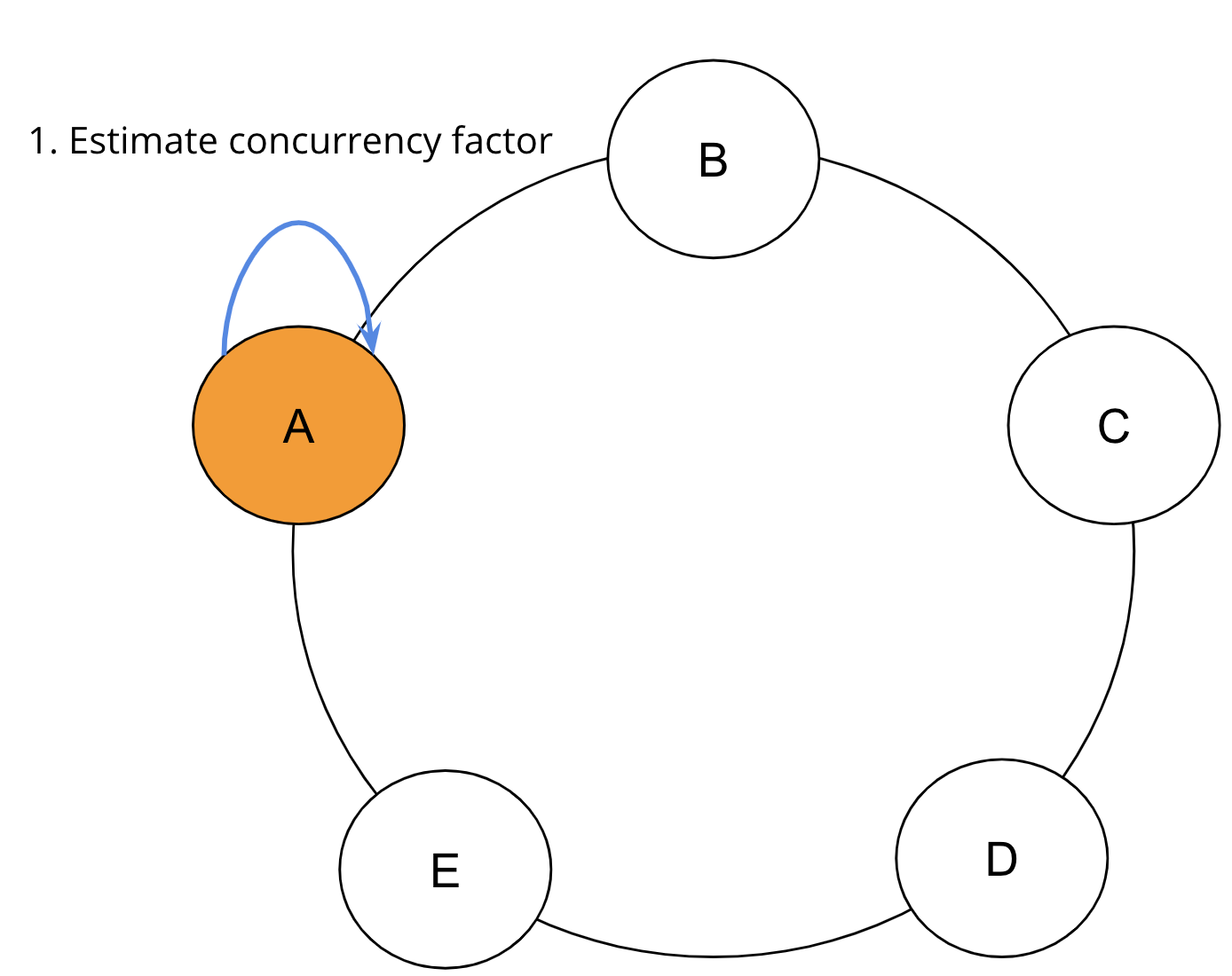
初期並行処理係数が確立されると、レンジ読み取りが開始されます。
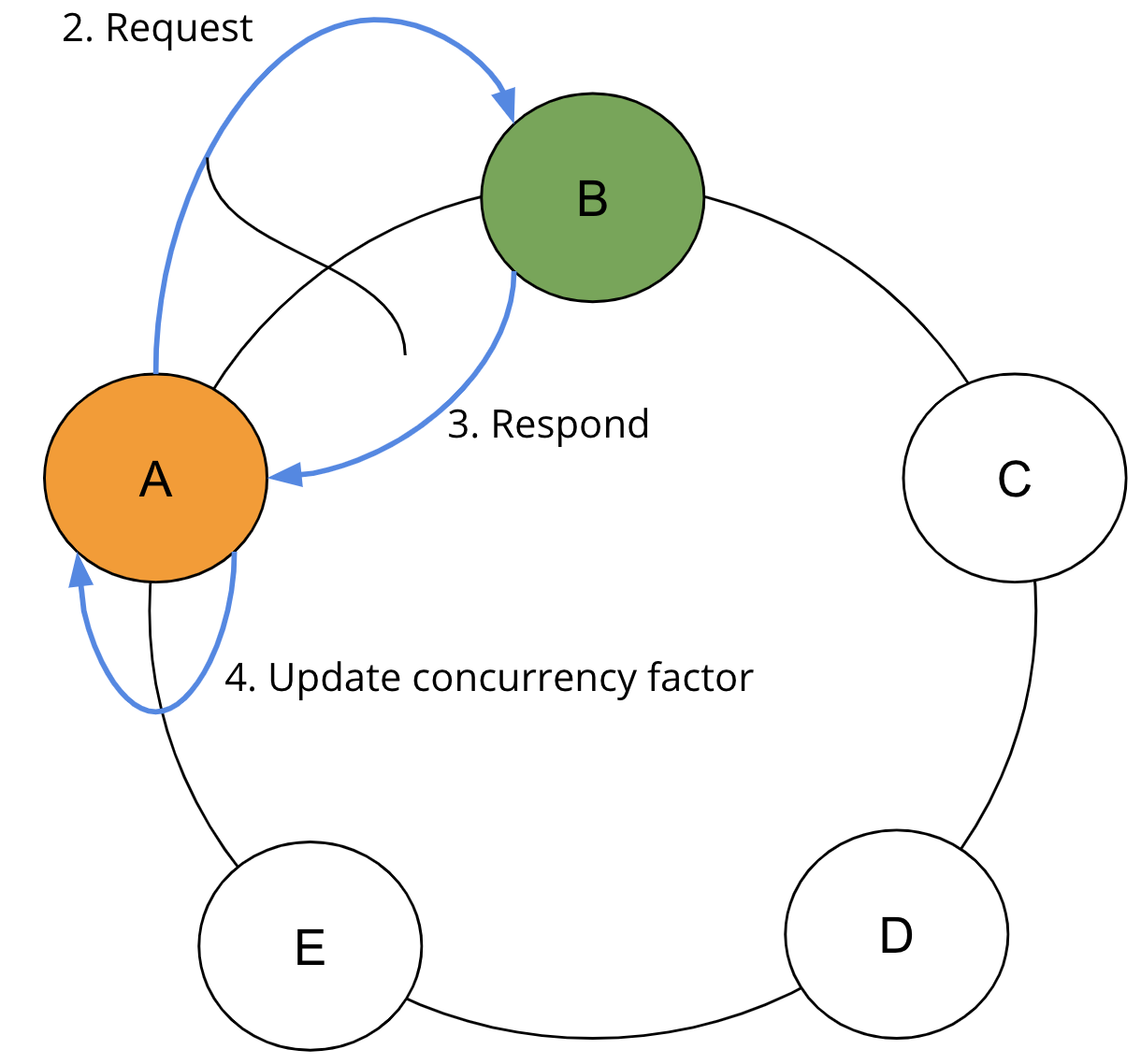
ステップ2では、SAIコーディネーターは、並行処理係数に基づいて、必要なレンジに並列でリクエストを送信します。ステップ3では、SAIコーディネーターは、要求されたレプリカからの応答を待ちます。そして、ステップ4では、SAIコーディネーターは結果を収集し、返された行とクエリ制限に基づいて並行処理係数を再計算します。
各ラウンドの完了時に、制限に達していない場合、すでに読み取られた結果の形状を考慮して並行処理係数が調整されます。最初のラウンドで結果が返されない場合、並行処理係数は、残りのトークンレンジの最小計算と並行処理係数の最大計算に即座に引き上げられます。結果が返された場合、並行処理係数が更新されます。SAIは、クエリ制限が満たされるまで、ステップ2、3、4を繰り返します。
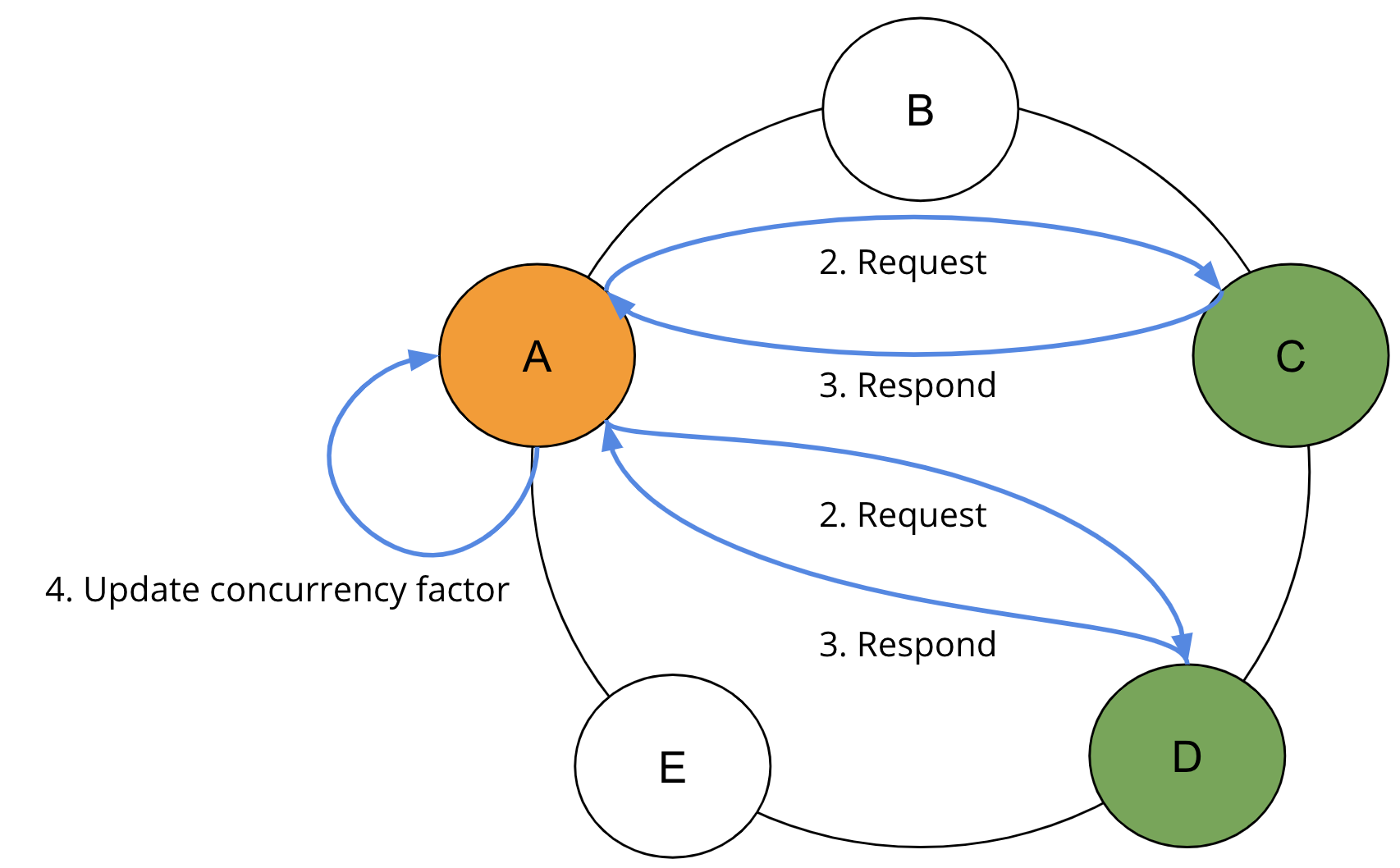
失敗したインデックスを持つレプリカへのクエリを避けるために、各ノードは独自のローカルインデックスの状態をgossip経由でピアに伝播します。コーディネーターでは、読み取りリクエストは、リクエストで使用されているクエリ不可能なインデックスを含むレプリカをフィルタリングします。ほとんどの場合、2回目のレプリカクエリのラウンドですべての必要な結果が返されるはずです。レプリカ周辺の結果の分布が極端に不均衡な場合は、さらなるラウンドが必要になる場合があります。
詳細:レプリカクエリの計画とビューの取得
レプリカがSAIコーディネーターからトークンレンジ読み取りリクエストを受信すると、ローカルインデックスのクエリが開始されます。SAIは、単一のクエリで利用可能なすべてのSAI列インデックスにアクセスできるようにするクエリプランを介してインデックス検索インターフェースを実装します。
クエリプランは、読み取りコマンドを介して渡された式を分析します。SAIは、指定された列のクエリ句を満たすためにどのインデックスを使用する必要があるかを決定します。列式がインデックスとペアリングされると、クエリコントローラーによって、各列インデックスのアクティブなSSTableインデックスのビューが取得されます。インフライトクエリで使用されるインデックスファイルをコンパクションで削除しないようにするために、クエリコントローラーは、インデックスファイルを読み取る前に、クエリのトークンレンジと交差するインデックスファイルのSSTableへの参照を取得しようとし、読み取りリクエストが完了するとそれらを解放します。
この時点で、各列インデックスから一致をストリームするためのトークンフローが作成されます。これらのフローと、それらをどのようにマージするかを決定するブールロジックは、Operationにラップされ、クエリプランコンポーネントに返されます。
SAIトークンフローフレームワークの役割
SAIクエリエンジンは、個々のSSTableインデックスと列インデックス全体の両方から、一致するパーティションのストリームをSAIが非同期的に反復処理、スキップ、およびマージする方法を定義するトークンフローフレームワークを中心に展開されます。SAIは、Cassandraリングトークン内のパーティション一致のコンテナを記述するためにトークンを使用します。
反復処理は、3つの操作の中で最も単純です。具体的には、ポスティングの反復処理には、行IDへの順次ディスクアクセス(チャンクキャッシュ経由)が含まれます。行IDは、リングトークンとパーティションキーオフセット情報をルックアップするために使用されます。
トークンスキップは、前のページング境界から続行する場合、またはトークン交差中に大きなトークンが見つかった場合に、一致しないトークンをスキップするために使用されます。
マッチングストリーミングとポストフィルタリングの例
個々の列インデックス(例:age = 44)の例を考えてみましょう。生成されるフローは、すべてのMemtableインデックスとすべてのSSTableインデックスの結合です。
-
SAIは、個々のトークンレンジでパーティション分割されたインスタンスを通じて、トークン順に各Memtableインデックスを「遅延」(つまり、一度に1つずつ)反復処理します。この機能により、リングの末尾に向かってデータの不要な検索から発生するであろうオーバーヘッドが削減されます。
-
オンディスクインデックス:SAIは、一致するすべてのSSTableインデックスの結合を返します。1つのSSTableインデックス内に、コンパクション中のメモリ制限のために、複数のセグメントが存在する可能性があります。Memtableインデックスと同様に、SAIはトークンソートされた順序でセグメントを遅延検索します。
クエリに複数のインデックス付き式(例:WHERE age=44 AND state='CA')がANDクエリオペレーターで接続されている場合、インデックス付き式の結果が交差され、すべてのインデックス付き式に一致するパーティションキーが返されます。
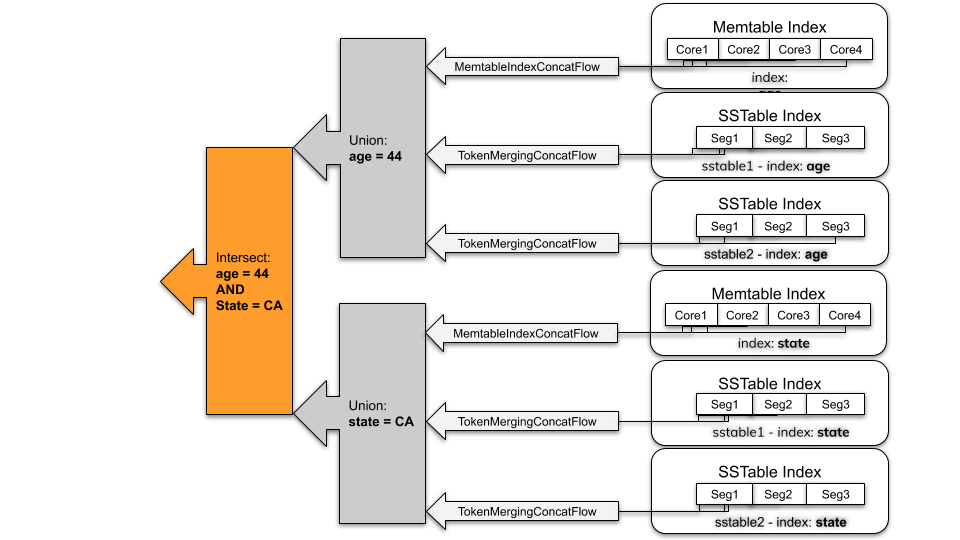
インデックス検索後、SAIはパーティションキーのフローを公開します。すべての単一のパーティションキーに対して、SAIは単一のパーティション読み取り操作を実行し、指定されたパーティション内の行を返します。行が実体化されると、SAIはフィルタツリーを使用して別のフィルタリングラウンドを適用します。SAIは、次の問題に対処するために、この後続のフィルタリングステップを実行します。
-
パーティション粒度:SAIはパーティションオフセットを追跡します。ワイドパーティションスキーマの場合、パーティション内のすべての行がインデックス式と一致するわけではありません。
-
墓石:SAIは墓石をインデックスしません。インデックス付きの行が、新たに追加された墓石によって隠されている可能性があります。
-
インデックス化されていない式:操作には、インデックス構造がない非インデックス式が含まれる場合があります。
次は何ですか?
ブログ「より良いデータモデルのためのより良いCassandraインデックス:ストレージアタッチドインデックスの導入」を参照してください。