













ストレージアタッチ型インデックス (SAI) の概念
ストレージアタッチ型インデックス (SAI) は、Cassandra データベースのための、高度にスケーラブルでグローバルに分散されたインデックスです。
Apache Cassandra の既存のインデックスと比較した SAI の主な利点は、次のとおりです。
-
AI アプリケーションのためのベクター検索を可能にする
-
同じテーブル上の複数のインデックス間で共通のインデックスデータを共有する
-
書き込み時のスケーラビリティの問題を軽減する
-
ディスク使用量を大幅に削減する
-
数値範囲の優れたパフォーマンス
-
インデックスのゼロコピーストリーミング
実際、SAI は Apache Cassandra で利用可能な最も機能豊富なインデックス機能を提供します。SAI は、ほぼすべての CQL データ型の任意の CQL テーブル列に列レベルのインデックスを追加します。
SAI は、次を基準としたフィルタリングを行うクエリを可能にします。
-
ベクター埋め込み
-
数値型とテキスト型の AND/OR ロジック
-
数値型とテキスト型の IN ロジック(値の配列を使用)
-
数値範囲
-
可変長ではない数値型
-
テキスト型の等価性
-
CONTAINS ロジック(コレクションの場合)
-
トークン化されたデータ
-
行認識クエリパス
-
大文字と小文字の区別(オプション)
-
Unicode 正規化(オプション)
利点
データベーステーブルの任意の列に基づいて 1 つ以上の SAI インデックスを定義することで、インデックス付きの列を指定する高性能なクエリを実行できるようになります。リレーショナルデータベースや複雑なインデックススキームと比較して、SAI はアプリ開発への道を加速させることで、効率性を向上させます。
SAI は Cassandra のストレージエンジンと深く統合されています。SAI 機能は、書き込み時にインメモリ Memtable とオンディスク SSTable の両方をインデックス化し、読み込み時にそれらのインデックス間の違いを解決します。その結果、SAI の設計は、コアデータベースの上に非常に少ない運用上の複雑さしかありません。スナップショットの作成からスキーマ管理、データの有効期限まで、SAI はコアデータベースが既に提供している機能とメカニズムと密接に統合されています。
SAI はゼロコピーストリーミング (ZCS) とも完全に互換性があります。そのため、クラスタでノードをブートストラップまたはデコミッションする場合、インデックスは SSTable と共に完全にストリーミングされ、受信ノード側でシリアル化または再構築されることはありません。
SAI のコアはフィルタリングエンジンであり、そうでなければ複数のクエリ固有のテーブルの維持に大きく依存するデータモデリングとクライアントアプリケーションを簡素化します。
パフォーマンス
SAI は、Apache Cassandra で利用可能な他のどのインデックス方法よりも優れたパフォーマンスを発揮します。
SAI は、セカンダリインデックス (2i) よりも多くの機能を提供し、ディスク容量を大幅に削減し、ディスク、インフラストラクチャ、運用にかかる総所有コスト (TCO) を削減します。読み込みパスのパフォーマンスに関しては、スループットとレイテンシに関して、他のインデックス方法と同等以上の性能を発揮します。
SAI 書き込みパスと読み込みパス
SAI は、基盤となるデータベースのストレージエンジンと深く統合されています。SAI はテーブルを抽象的にインデックス化しません。代わりに、SAI は書き込み時に **Memtable** とソート済み文字列テーブル (**SSTable**) をインデックス化し、読み込み時にそれらのインデックス間の違いを解決します。各 Memtable は、特定のデータベーステーブルに固有のインメモリデータ構造です。Memtable はライトバックキャッシュに似ています。各 SSTable は、データベースが定期的に Memtable を書き込む不変のデータファイルです。SSTable はディスク上に順次保存され、各データベーステーブルに対して維持されます。
このトピックでは、SAI インデックスライフサイクルを検討し、SAI の読み込みパスと書き込みパスの詳細について説明します。
SAI 書き込みパス
SAI インデックスは、データが CQL テーブルに書き込まれる前に作成することも、データが書き込まれた後に作成することもできます。復習として、CQL テーブルに書き込まれたデータは、最初に Memtable に書き込まれ、データが Memtable からフラッシュされると SSTable に書き込まれます。SAI インデックスが作成されると、現在の Memtable に対するすべての変更が SAI に通知されます。他のデータと同様に、SAI は挿入と更新のインデックスを更新し、Apache Cassandra はこれらをまったく同じ方法で処理します。SAI は、パーティションの削除、範囲墓石、行の削除もサポートしています。クエリで削除操作が実行された場合、SAI はポストフィルタリングステップでインデックスの変更を処理します。その結果、SAI は頻繁に削除される列をインデックス化する場合に特別なペナルティを課しません。
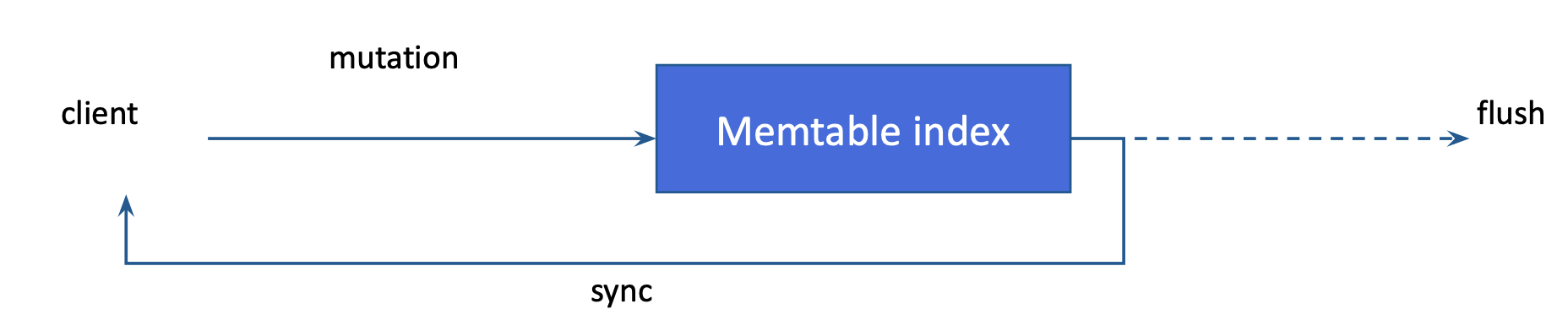
挿入または更新にインデックス付き列の有効なコンテンツが含まれている場合、そのコンテンツは **Memtable インデックス** に追加され、更新された行の主キーがインデックス付きの値に関連付けられます。SAI は、新しいエントリの増分ヒープ消費量の推定値を計算します。この推定値は、基盤となる Memtable のヒープ使用量に対してカウントされます。この機能は、テーブルにインデックスされる列が増えるにつれて、Memtable のフラッシュレートが増加し、フラッシュされた SSTable のサイズが小さくなることも意味します。ライブ Memtable インデックス全体の合計書き込み数と推定ヒープ使用量は、メトリクスとして公開されています。SAI メトリクス を参照してください。
Memtable フラッシュ
SAI は、追加のインメモリ表現を作成するのではなく、フラッシュしきい値に達したときに Memtable インデックスの内容を直接ディスクにフラッシュします。これは、Memtable インデックスが用語/値でソートされ、次に主キーでソートされるため可能です。フラッシュが発生すると、SSTable が書き込まれる際に、SAI はインデックス付きの列ごとに新しい SSTable インデックスを書き込みます。
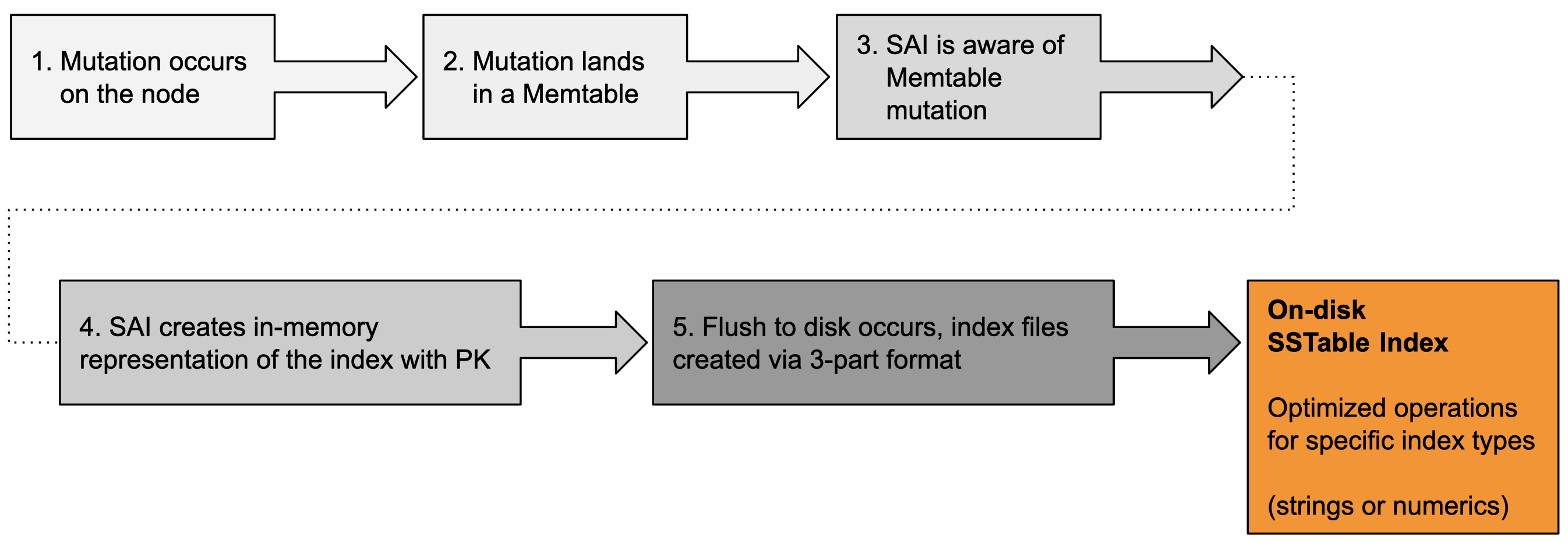
フラッシュ操作は 2 フェーズのプロセスです。最初のフェーズでは、行が新しい SSTable に書き込まれます。各行に対して、行 ID が生成され、3 つのインデックスコンポーネントが作成されます。コンポーネントは次のとおりです。
-
行 ID とその対応するトークン値のオンディスクマッピング(SAI は Murmur3Partitioner をサポート)
-
SSTable パーティションオフセット
-
主キーとその行 ID の一時的なマッピング。これは後続のフェーズで使用されます。
最初のコンポーネントファイルと 2 番目のコンポーネントファイルの内容は、その序数が行 ID に対応する圧縮配列です。
2 番目のフェーズでは、すべての行が新しい SSTable に書き込まれ、共有 SSTable レベルのインデックスコンポーネントが完了した後、SAI はインデックス付きの列ごとにインデックス化作業を開始します。具体的には、2 番目のフェーズで、SAI は Memtable インデックスを反復処理して、用語とそれらのトークンでソートされた行 ID のペアを生成します。このイテレータは、最初のフェーズで構築された一時的なマッピング構造を使用して、主キーを行 ID に変換します。次に、用語イテレータ(投稿付き)は、インデックス付きの要素が文字列列か数値列かによって、個別の書き込みコンポーネントに渡されます。
文字列の場合、SAI インデックスライターは各用語を反復処理し、最初にその投稿をディスクに書き込み、次に、オンディスクのバイト順序トライにある新しいエントリ(用語自体用)のペイロードとして、それらの投稿のオフセットを記録します。数値の場合、SAI は数値インデックスの書き込みを 2 つのステップに分離します。
用語はバランスのとれた kd ツリーライターに渡され、kd ツリーがディスクに書き込まれます。ツリーの葉ブロックが書き込まれると、その投稿は一時的にメモリに記録されます。次に、それらの一時的な投稿を使用して、葉とインデックスノードのさまざまなレベルでオンディスクの投稿が構築されます。
列インデックスのフラッシュが完了すると、成功を示す特別な空のマーカーファイルがフラグ付けされます。この手順は、起動時と増分再構築操作で使用され、次の場合に区別されます。
-
列の SSTable インデックスファイルがありません。
-
インデックス可能なデータが存在しない場合、例えばSSTableに墓石のみが含まれる場合などです。(墓石とは、行内のマーカーで、列が削除されたことを示します。コンパクション中に、マークされた列は削除されます。)
その後、SAIは列に対してフラッシュされたMemtableインデックスの数をカウントするカウンタを増分し、秒あたりにフラッシュされたセルの数をヒストグラムに追加します。
コンパクションがトリガーされた場合
Apache Cassandraはコンパクションを使用してSSTableをマージすることを思い出してください。コンパクションは、各一意の行のすべてのバージョンを収集し、SSTableから各行の列の最新バージョン(タイムスタンプによる)を使用して、1つの完全な行を組み立てます。マージプロセスは、各SSTable内でパーティションキーによって行がソートされており、マージプロセスがランダムI/Oを使用しないため、パフォーマンスに優れています。各行の新しいバージョンは新しいSSTableに書き込まれます。古いバージョンと、削除の準備ができた行は、古いSSTableに残され、保留中の読み込みが完了すると削除されます。
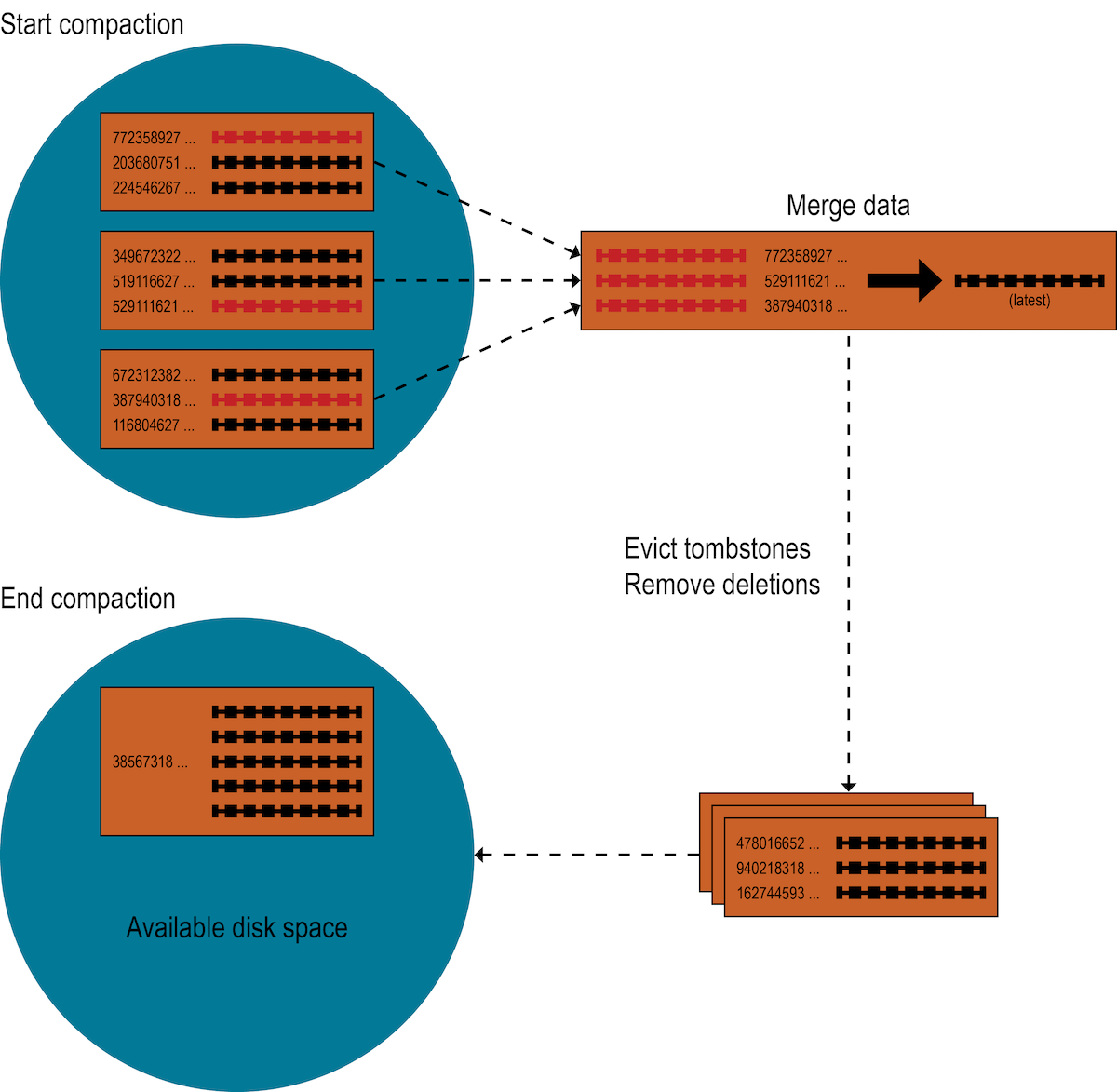
SAIの場合、コンパクションがトリガーされると、各インデックスグループはSSTable Flush Observerを作成し、新しく圧縮されたデータからすべての添付された列インデックスをそれぞれのSSTableライターインスタンスに書き込むプロセスを調整します。Memtableフラッシュ(インデックス付きの用語は既にソートされている)とは異なり、コンパクション中にマージされたデータを反復処理する際、SAIはインデックス付きの値とその行IDをバッファリングし、トークン順に追加します。
使用可能なヒープリソースを使い果たすなどの問題を回避するために、SAIは累積セグメントバッファを使用します。これは、独自の計算を使用してディスクに同期的にフラッシュされます。次に、各セグメントはセグメント行IDの**オフセット**を記録し、セグメント行ID(SSTable行ID - セグメント行IDオフセット)のみを保存します。SAIは、すべてのセグメントを書き直すコストを回避し、パーティション制限クエリとページング範囲クエリの費用を削減するために、セグメントを同じファイルに同期的にフラッシュします。これは、検索範囲を縮小するためです。
列ごとのインデックス付きポスティング、SSTableオフセット、SSTableパーティションからのオンディスクレイアウト
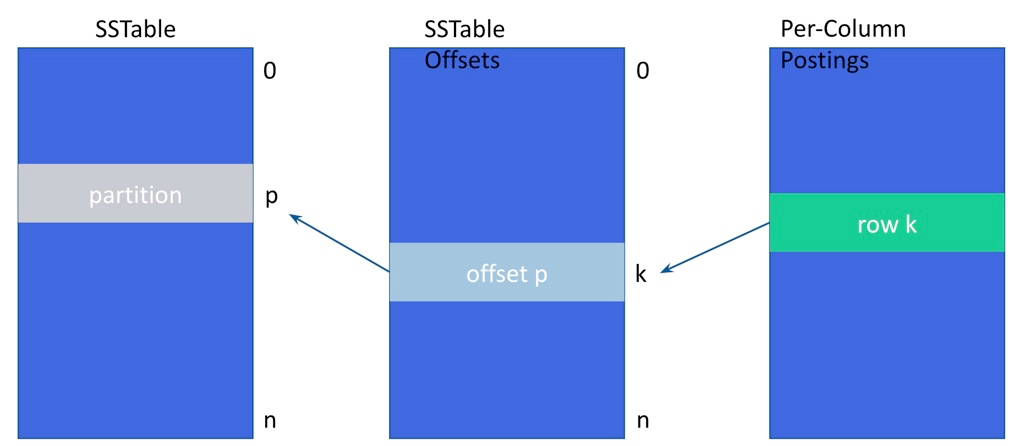
実際のセグメントフラッシュプロセスは、Memtableフラッシュと非常によく似ています。ただし、バッファリングされた用語は、それぞれのタイプ固有のオンディスク構造にポスティングと共に書き込む前にソートされます。特定のインデックスのコンパクションの最後に、特別な空のマーカーファイルにフラグが立てられて成功を示し、セグメントの数がSAIメトリクスに記録されます。グローバルインデックスメトリクスを参照してください。
コンパクションタスク全体が完了すると、SAIはトランザクション中に追加および削除されたSSTableを含むSSTableリスト変更通知を受信します。SSTableコンテキストマネージャーとインデックスビューマネージャーは、古いSSTableインデックスを新しいSSTableインデックスとアトミックに置き換える役割を担います。この時点で、新しいSSTableインデックスがクエリで使用できるようになります。
SAI読み取りパス
このセクションでは、SAIコーディネーターによってインデックスクエリがどのように処理され、レプリカによって実行されるかを説明します。レガシーのセカンダリインデックスでは、クエリごとに最大1つの列インデックスが使用されるのに対し、SAIはクエリプランを実装しており、単一クエリですべての利用可能な列インデックスを使用できます。
SAI読み取り操作の全体的な流れは次のとおりです。
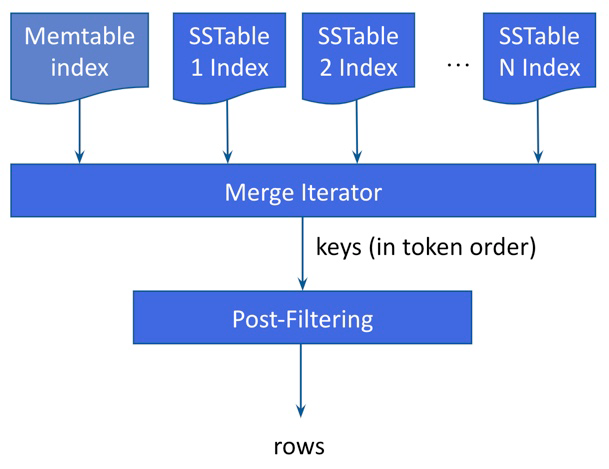
インデックスの選択とコーディネーター処理
クエリが提示されると、SAIコーディネーターが最初に実行するアクションは、1つ以上のインデックスを活用するために、最も選択的なインデックスを特定することです。最も選択的なインデックスとは、推定結果行計算から最も低い値を返すことによって、フィルタリング空間と最終的な結果の数を最も積極的に絞り込むインデックスです。複数のSAIインデックスが存在する場合(つまり、各SAIインデックスが異なる列に基づいているが、クエリが複数の列を含む場合)、最初にどのSAIインデックスが選択されるかは問題ではありません。
読み取り操作に最適なインデックスが選択されると、そのインデックスは読み取りコマンドに埋め込まれ、分散範囲読み取り装置に入力されます。分散範囲読み取りは、トークン順に1回以上のラウンドでApache Cassandraクラスタにクエリを実行します。SAIコーディネーターは、ローカルデータとクエリ制限に基づいて範囲ごとの行数である**同時実行ファクター**を推定し、接触する範囲の数を決定します。各ラウンドで、同時実行ファクターは、並列にクエリされるレプリカの数を決定します。
最初のラウンドが始まる前に、SAIはステップ1としてここに示す独自の計算を介して初期の同時実行ファクターを推定します。
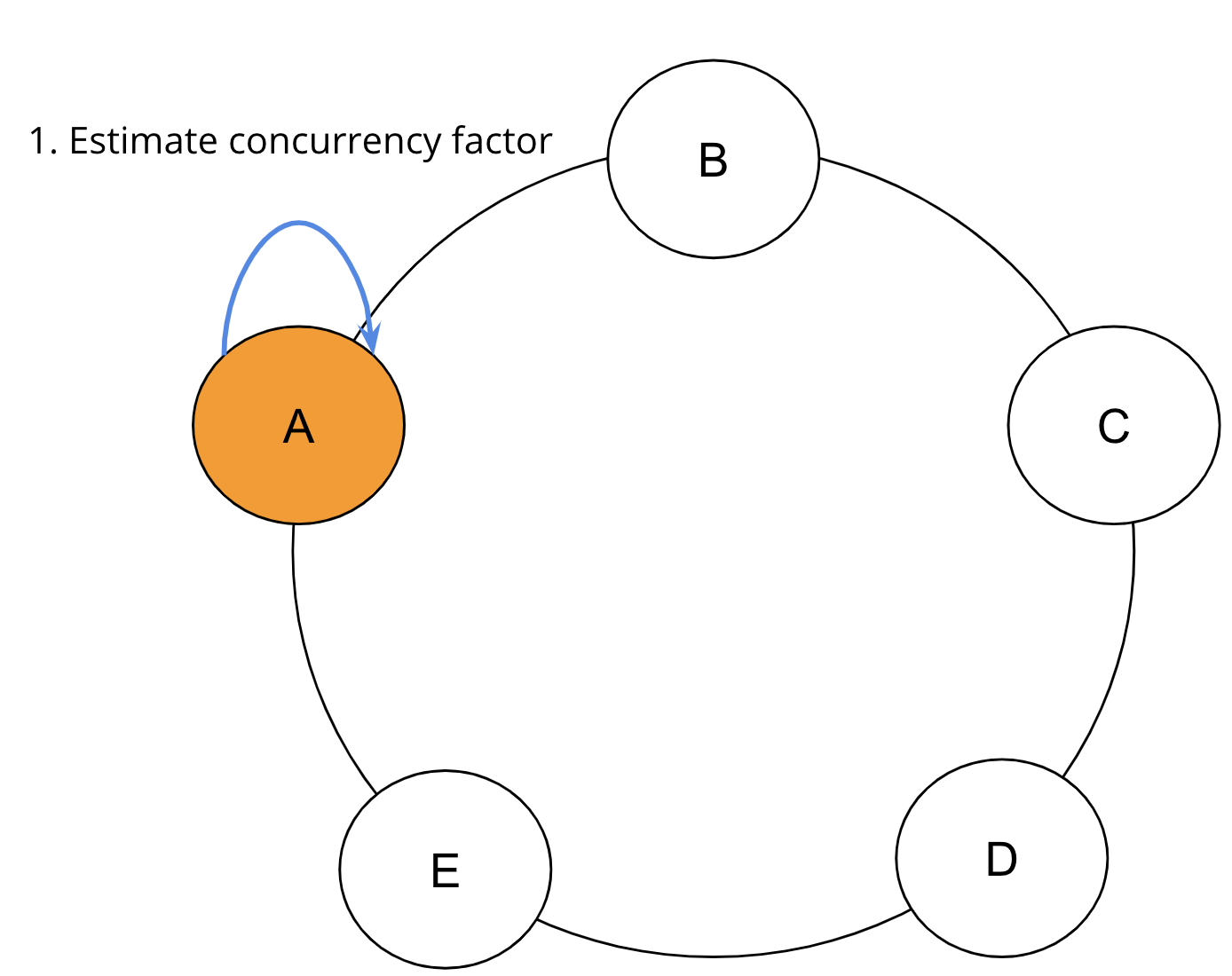
初期の同時実行ファクターが確立されると、範囲読み取りが開始されます。
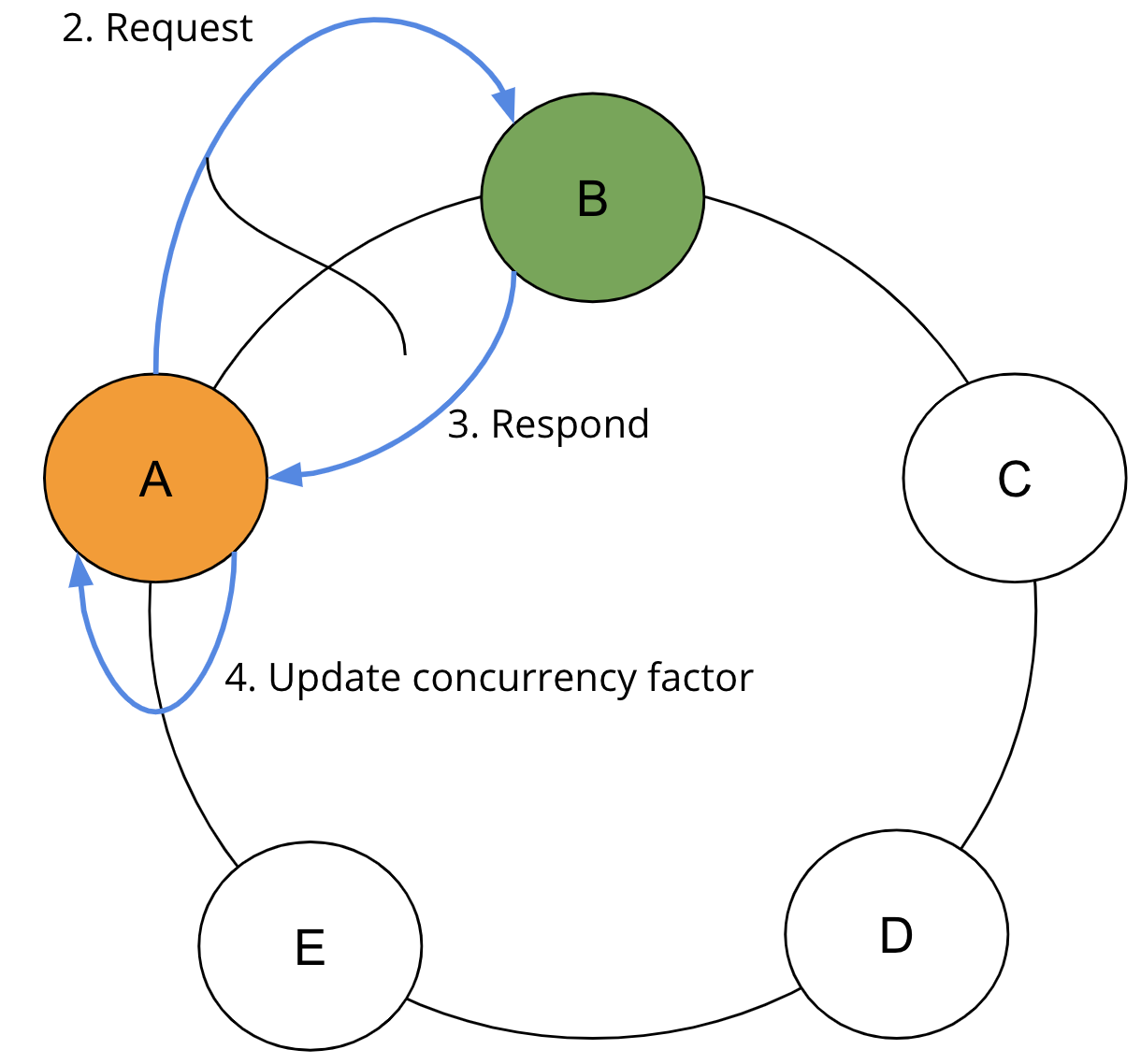
ステップ2で、SAIコーディネーターは同時実行ファクターに基づいて必要な範囲に並列でリクエストを送信します。ステップ3で、SAIコーディネーターはリクエストされたレプリカからの応答を待ちます。ステップ4で、SAIコーディネーターは結果を収集し、返された行とクエリ制限に基づいて同時実行ファクターを再計算します。
各ラウンドの完了時に、制限に達していない場合、既に読み取られた結果の形状を考慮して同時実行ファクターが調整されます。最初のラウンドから結果が返されない場合、同時実行ファクターは、残りのトークン範囲の最小計算と同時実行ファクターの最大計算にすぐに増やされます。結果が返された場合、同時実行ファクターが更新されます。クエリ制限が満たされるまで、SAIはステップ2、3、4を繰り返します。
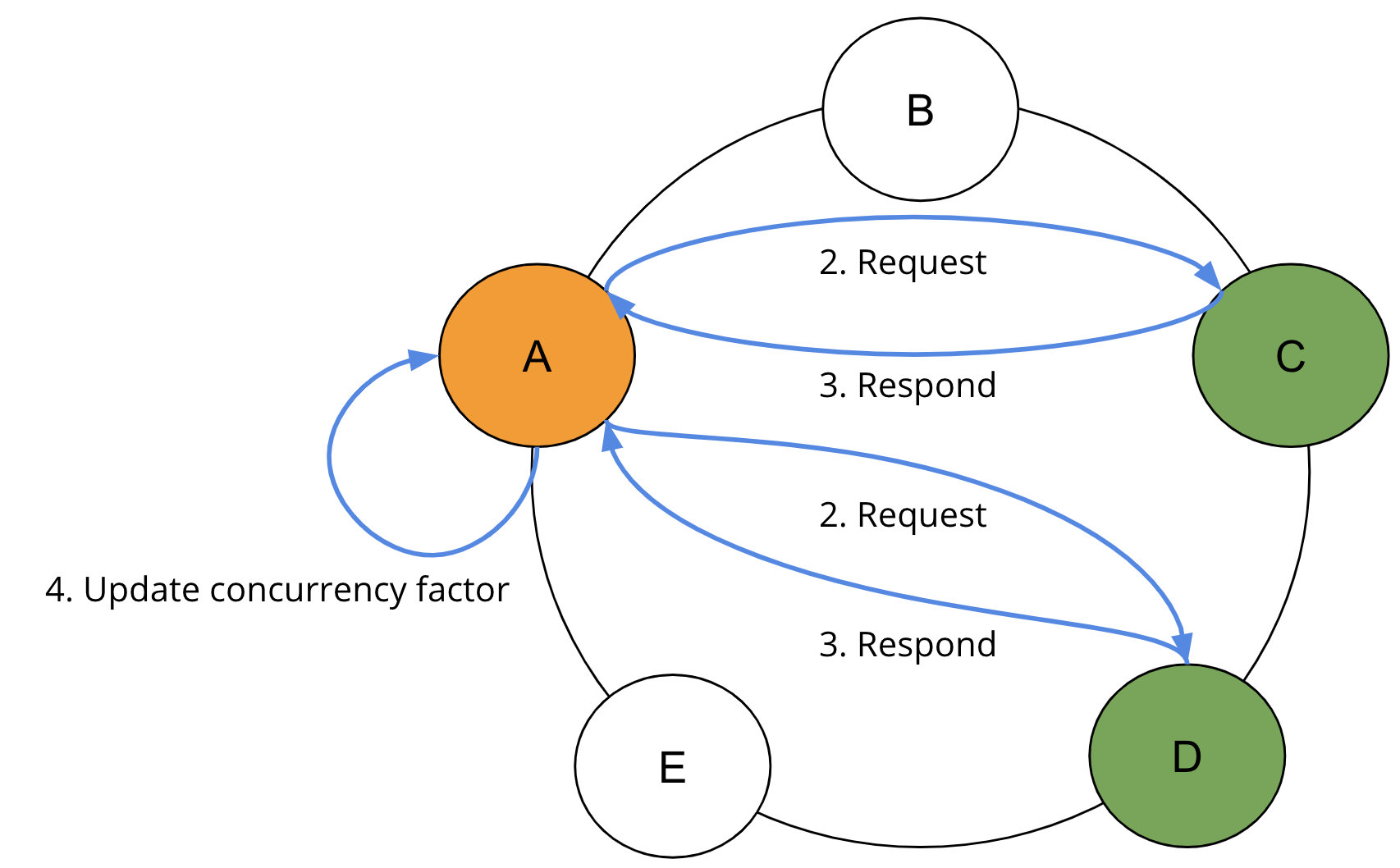
インデックスに障害が発生したレプリカにクエリを実行するのを回避するために、各ノードはゴシップを介して独自のローカルインデックスステータスをピアに伝播します。コーディネーターでは、読み取りリクエストは、リクエストで使用されているクエリ不可能なインデックスを含むレプリカをフィルタリングします。ほとんどの場合、2回目のレプリカクエリで必要なすべての結果が返されます。レプリカ間の結果の分布が非常に不均衡な場合、さらにラウンドが必要になる場合があります。
詳細:レプリカクエリプランニングとビュー取得
レプリカがSAIコーディネーターからトークン範囲読み取りリクエストを受信すると、ローカルインデックスクエリが開始されます。SAIはクエリプランを介してインデックス検索インターフェースを実装しており、単一クエリですべての利用可能なSAI列インデックスにアクセスできます。
クエリプランは、読み取りコマンドを介して渡された式の分析を実行します。SAIは、指定された列のクエリ句を満たすために使用するインデックスを決定します。列式がインデックスとペアリングされると、クエリコントローラーによって各列インデックスのアクティブなSSTableインデックスのビューが取得されます。進行中のクエリで使用されているインデックスファイルがコンパクションによって削除されるのを回避するために、クエリコントローラーはインデックスファイルを読み取る前に、クエリのトークン範囲と交差するインデックスファイルのSSTableへの参照を取得しようと試み、読み取りリクエストが完了するとそれらを解放します。
この時点で、各列インデックスから一致をストリーミングするためのトークンフローが作成されます。それらのフローと、それらがどのようにマージされるかを決定するブール論理は、オペレーションにまとめられ、クエリプランコンポーネントに返されます。
SAIトークンフローフレームワークの役割
SAIクエリエンジンは、SAIが個々のSSTableインデックスと列インデックス全体の両方から一致するパーティションのストリームを非同期的に反復処理、スキップ、マージする方法を定義するトークンフローフレームワークを中心に展開されています。SAIは、Cassandraリングトークン内のパーティション一致のコンテナを表すトークンを使用します。
反復処理は、3つの操作の中で最も単純なものです。具体的には、ポスティングの反復処理には、チャンクキャッシュを介した行IDへのシーケンシャルディスクアクセスが含まれ、これを使用してリングトークンとパーティションキーオフセット情報をルックアップします。
トークンスキップは、前のページング境界から継続する場合、またはトークン交差中により大きなトークンが見つかった場合に、一致しないトークンをスキップするために使用されます。
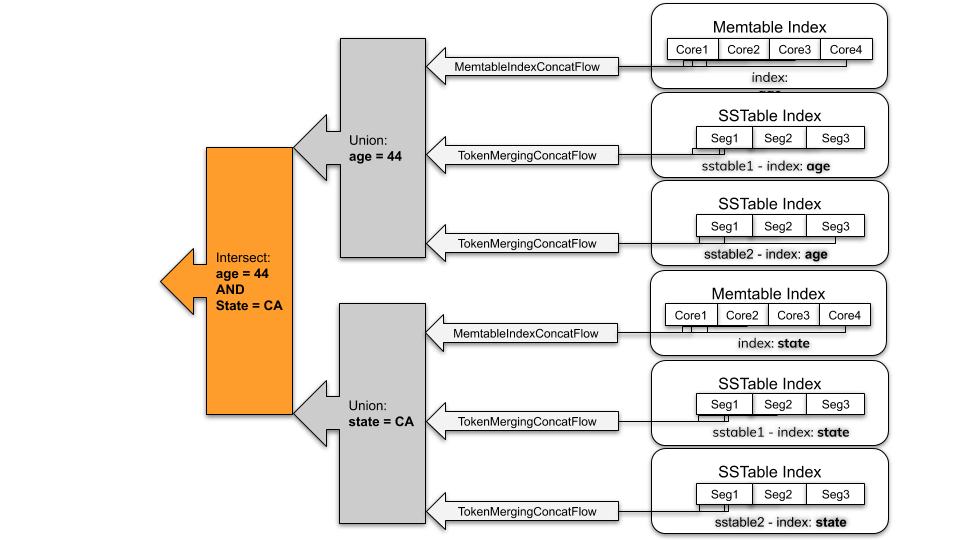
一致ストリーミングとポストフィルタリングの例
個々の列インデックス(例:age = 44)の例を考えてみましょう。生成されるフローは、すべてのMemtableインデックスとすべてのSSTableインデックスの和集合です。
-
SAIは、個々のトークン範囲でパーティション化されたインスタンスを介して、トークン順に各Memtableインデックスを「遅延的に」(つまり、一度に1つずつ)反復処理します。この機能により、リングの最後の方にあるデータの不要な検索から発生するオーバーヘッドが軽減されます。
-
オンディスクインデックス:SAIは、すべてのマッチングSSTableインデックスの和集合を返します。1つのSSTableインデックス内には、コンパクション中のメモリ制限のために複数のセグメントが存在する場合があります。Memtableインデックスと同様に、SAIはトークンソート順にセグメントを遅延的に検索します。
クエリに複数のインデックス式(例:WHERE age=44 AND state='CA')がANDクエリ演算子で接続されている場合、インデックス式の結果は交差され、すべてのインデックス式に一致するパーティションキーが返されます。
インデックス検索後、SAIはパーティションキーのフローを公開します。SAIは、パーティションキーごとに単一のパーティション読み取り操作を実行し、指定されたパーティション内の行を返します。行がマテリアライズされると、SAIはフィルタツリーを使用して別のフィルタリングラウンドを適用します。SAIは、次の点を解決するために、この後続のフィルタリングステップを実行します。
-
パーティション粒度:SAIはパーティションオフセットを追跡します。ワイドパーティションスキーマの場合、パーティション内のすべての行がインデックス式と一致するとは限りません。
-
墓石:SAIは墓石をインデックスしません。インデックス付きの行が新しく追加された墓石によってシャドウされている可能性があります。
-
インデックスなしの式:操作には、インデックス構造が存在しないインデックスなしの式が含まれる場合があります。
次のステップ
ブログ「より良いデータモデルのためのより良いCassandraインデックス:ストレージアタッチ型インデックスの導入」を参照してください。